本文来自 Itimetraveler’s Blog: 【算法】10亿int型数,统计只出现一次的数
题目
10亿int整型数,以及一台可用内存为1GB的机器,时间复杂度要求O(n),统计只出现一次的数?
分析
首先分析多大的内存能够表示10亿的数呢?一个int型占4字节,10亿就是40亿字节(很明显就是4GB),也就是如果完全读入内存需要占用4GB,而题目只给1GB内存,显然不可能将所有数据读入内存。
我们先不考虑时间复杂度,仅考虑解决问题。那么接下来的思路一般有两种。
一种是位图法,如果各位老司机有经验的话很快会想到int整型数是4字节(Byte),也就是32位(bit),如果能用一个bit位来标识一个int整数那么存储空间将大大减少。另一种是分治法,内存有限,我想办法分批读取处理。下面大致分析一下两种思路。
1、位图法(Bitmap)
位图法是基于int型数的表示范围这个概念的,用一个bit位来标识一个int整数,若该位为1,则说明该数出现;若该位为0,则说明该数没有出现。一个int整型数占4字节(Byte),也就是32位(bit)。那么把所有int整型数字表示出来需要2^32 bit的空间,换算成字节单位也就是2^32/8 = 2^29 Byte,大约等于512MB
|
|
这下就好办了,只需要用512MB的内存就能存储所有的int的范围数。
具体方案
那么接下来我们只需要申请一个int数组长度为 int tmp[N/32+1]即可存储完这些数据,其中N代表要进行查找的总数(这里也就是2^32),tmp中的每个元素在内存在占32位可以对应表示十进制数0~31,所以可得到BitMap表:
- tmp[0]:可表示0~31
- tmp[1]:可表示32~63
- tmp[2]可表示64~95
- ~~
假设这10亿int数据为:6,3,8,32,36,……,那么具体的BitMap表示为:
[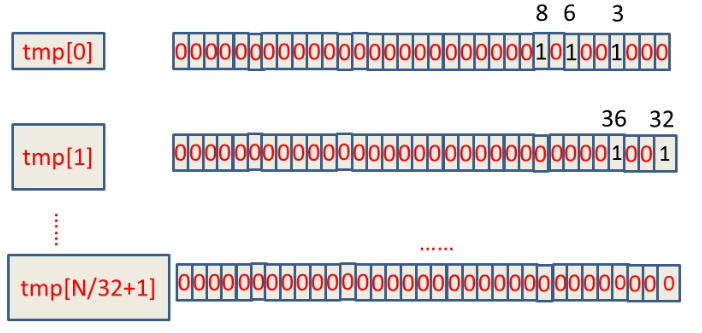](https://itimetraveler.github.io/gallery/bitmap/37237-20160302211041080-958649492.png)
(1). 如何判断int数字放在哪一个tmp数组中:将数字直接除以32取整数部分(x/32),例如:整数8除以32取整等于0,那么8就在tmp[0]上;
(2). 如何确定数字放在32个位中的哪个位:将数字mod32取模(x%32)。上例中我们如何确定8在tmp[0]中的32个位中的哪个位,这种情况直接mod上32就ok,又如整数8,在tmp[0]中的第8 mod上32等于8,那么整数8就在tmp[0]中的第八个bit位(从右边数起)。
然后我们怎么统计只出现一次的数呢?每一个数出现的情况我们可以分为三种:0次、1次、大于1次。也就是说我们需要用2个bit位才能表示每个数的出现情况。此时则三种情况分别对应的bit位表示是:00、01、11
我们顺序扫描这10亿的数,在对应的双bit位上标记该数出现的次数。最后取出所有双bit位为01的int型数就可以了。
Bitmap拓展
位图(Bitmap)算法思想比较简单,但关键是如何确定十进制的数映射到二进制bit位的map图。
优点:
- 运算效率高,不许进行比较和移位;
- 占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M
缺点:所有的数据不能重复。即不可对重复的数据进行排序和查找。
建立了Bit-Map之后,就可以方便的使用了。一般来说Bit-Map可作为数据的查找、去重、排序等操作。比如以下几个例子:
1、在3亿个整数中找出重复的整数个数,限制内存不足以容纳3亿个整数
对于这种场景可以采用2-BitMap来解决,即为每个整数分配2bit,用不同的0、1组合来标识特殊意思,如00表示此整数没有出现过,01表示出现一次,11表示出现过多次,就可以找出重复的整数了,其需要的内存空间是正常BitMap的2倍,为:3亿*2/8/1024/1024=71.5MB。
具体的过程如下:扫描着3亿个整数,组BitMap,先查看BitMap中的对应位置,如果00则变成01,是01则变成11,是11则保持不变,当将3亿个整数扫描完之后也就是说整个BitMap已经组装完毕。最后查看BitMap将对应位为11的整数输出即可。
2、对没有重复元素的整数进行排序
对于非重复的整数排序BitMap有着天然的优势,它只需要将给出的无重复整数扫描完毕,组装成为BitMap之后,那么直接遍历一遍Bit区域就可以达到排序效果了。
举个例子:对整数4、3、1、7、6进行排序:
[](https://itimetraveler.github.io/gallery/bitmap/37237-20160302215109220-1394239868.png)
直接按Bit位输出就可以得到排序结果了。
3、已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话。
4、2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数
将bit-map扩展一下,用2bit表示一个数即可:0表示未出现;1表示出现一次;2表示出现2次及以上,即重复,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
最后放一个使用Byte[]数组存储、读取bit位的示例代码,来自利用位映射原理对大数据排重:
|
|
2、分治法
分治法目前看到的解决方案有哈希分桶(Hash Buckets)和归并排序两种方案。
哈希分桶的思想是先遍历一遍,按照hash分N桶(比如1000桶),映射到不同的文件中。这样平均每个文件就10MB,然后分别处理这1000个文件,找出没有重复的即可。一个相同的数字,绝对不会夸文件,有hash做保证。因为算法具体还不甚了解,这里先不做详细介绍。
归并排序的思想可以参考这篇文章:面试题之10亿正整数问题续–关于多通道排序的问题
