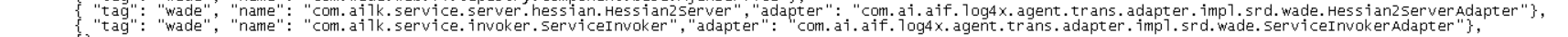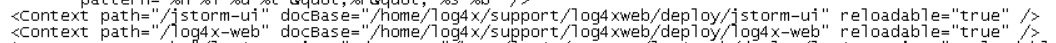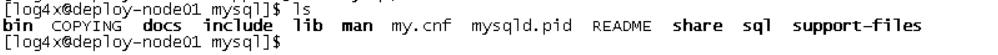author: made by lvshen
Log4X平台介绍
Log4X是负责实现日志采集、分析、展示的产品。针对分布式系统环境下的分散日志,进行记中存储、分析以及运用的日志管理平台。
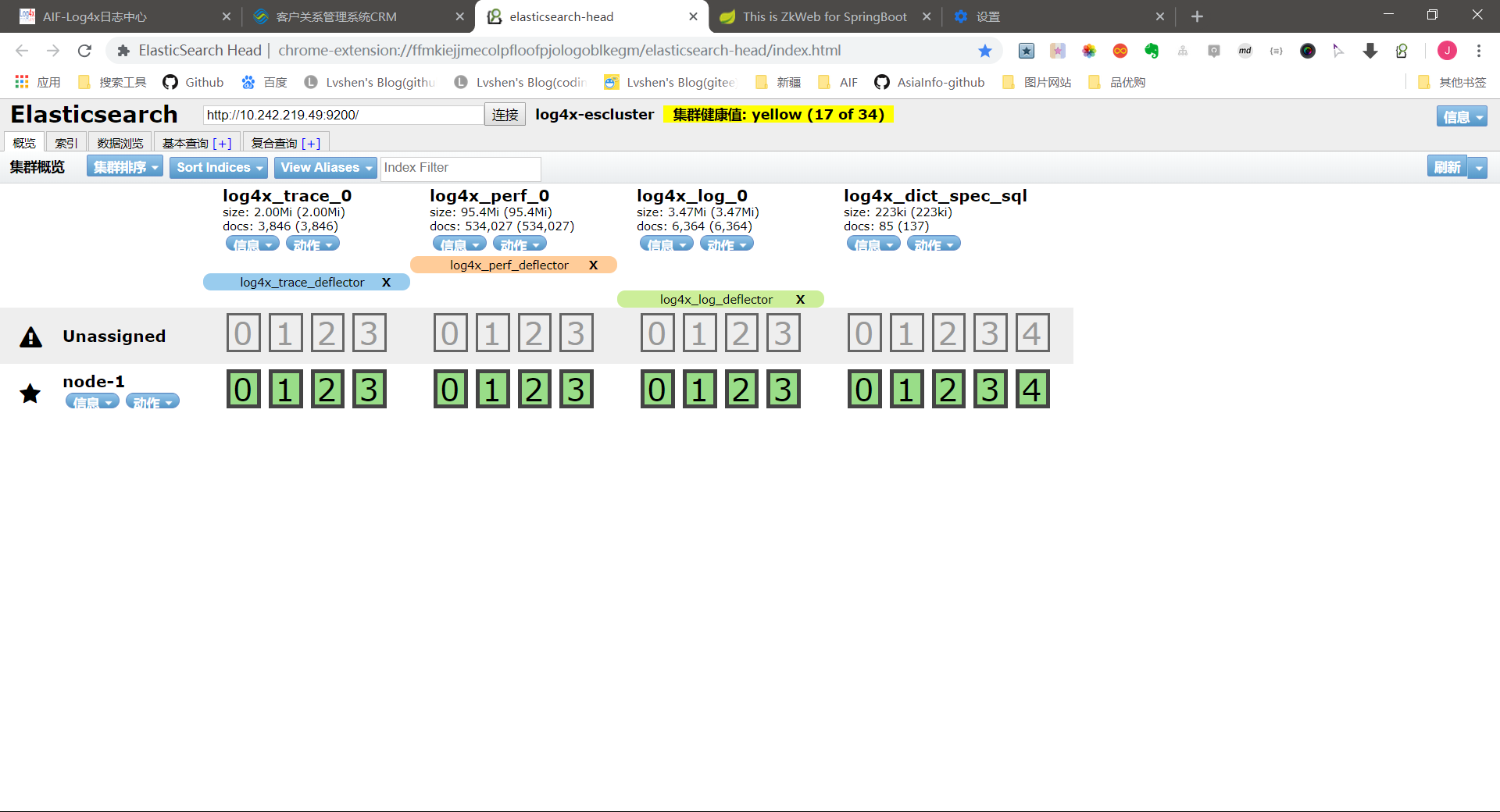
web页面展示
web页面缩略图
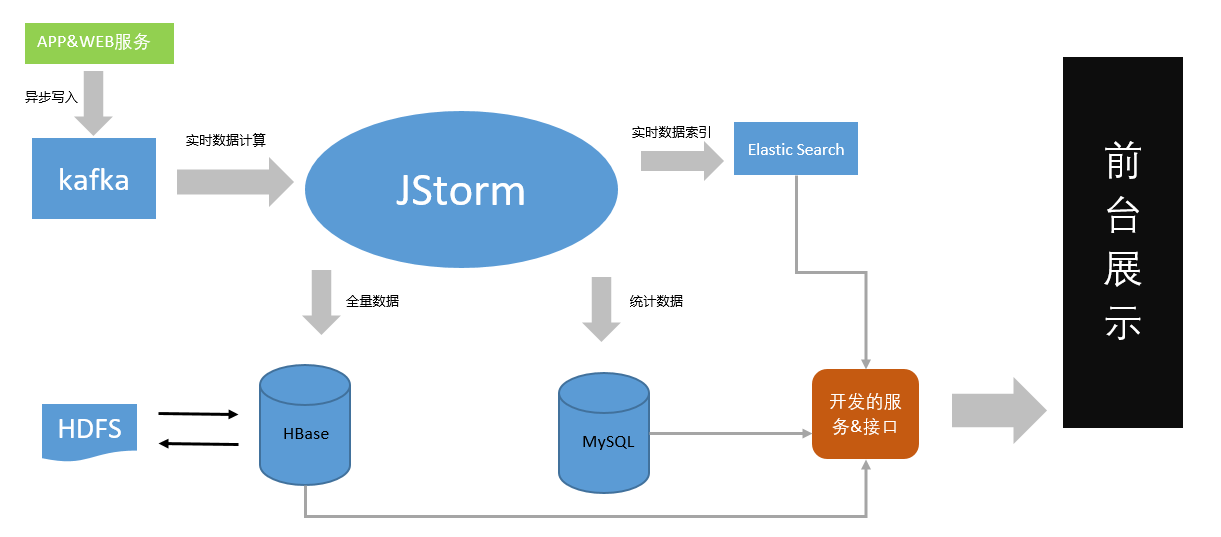
架构图
log4x架构图
如上图是数据的流向架构图。
Log4x的客户端,通过Agent和Client将采集部分代码通过字节码增强或者植入代码到应用服务(APP&WEB)系统中,完成数据的采集,并发送到kafka,属于日志采集模块;以Strom集群作为实时流处理的核心系统,完成Trace日志的处理、统计和预警功能,并将数据存储于Hbase和RDBMS中,属于日志分析模块子系统;日志应用服务器完成日志统计结果的查询和搜索,通过CSF框架提供数据供web端展现,属于日志可视化子系统。
APP应用端部署
添加jar包
为了获取APP的日志以及调用链等数据,这里CRM应用需要做一些配置。在deploy用户下,路径:deploy@10.242.219.49:/home/deploy/subversion/library/wadelib/common/lib/需要添加Log4X相关的jar包
1 2 3 4 5 6 7
| slf4j-log4j12-1.7.6.jar slf4j-api-1.7.6.jar scala-library-2.11.7.jar log4x-appender-1.0.1.jar log4x-client-3.0.0.jar log4x-common-1.0.0.jar log4x-logging-1.0.0.jar snakeyaml-1.17.jar snappy-java-1.1.1.7.jar jackson-databind-2.7.5.jar jackson-core-2.7.5.jar jackson-annotations-2.7.5.jar disruptor-3.3.6.jar metrics-core-2.2.0.jar log4j-1.2.17.jar kafka-clients-0.8.2.2.jar kafka_2.11-0.8.2.2.jar commons-dbcp-1.4.jar commons-pool-1.5.4.jar
|
修改配置文件log4j.properties
路径:deploy@10.242.219.49:/home/deploy/subversion/runtime-config/app/config/
需要添加log4x的日志采集:
log4x日志开关
log4x其他配置:
log4x其他配置
新增log4x.yaml
新增文件有几个地方需要注意:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
| traceEnabled: true logEnabled: true metricEnabled: true ... producerType: kafka message: default: topic: LOG4X-MSG-TOPIC bufferFullPolicy: discard trace: topic: LOG4X-TRACE-TOPIC sampleRatio: 1 bufferFullPolicy: discard log: topic: LOG4X-LOG-TOPIC metric: topic: LOG4X-METRIC-TOPIC thread: enabled: true category: - name: Wade pattern: 'wade-container' kafka: default: bootstrap.servers: 10.242.219.49:9092 file: dataDir: "${user.home}/log4x/data"
|
至此deploy用户配置结束
app用户配置
登陆app用户,在/home/app/sbin/setEnv.sh文件中添加:
1
| JAVA_OPTS="$JAVA_OPTS -javaagent:${HOME}/support/agent/log4x-agent.jar"
|
在/home/app/support路径下添加:agent客户端(由log4x方提供),agent目录如下:
agent目录
这里有一个aif-log4x-adapter-srd-5.5.0.jar是我们为了获取调用链而写的埋点类。下面介绍下埋点方法
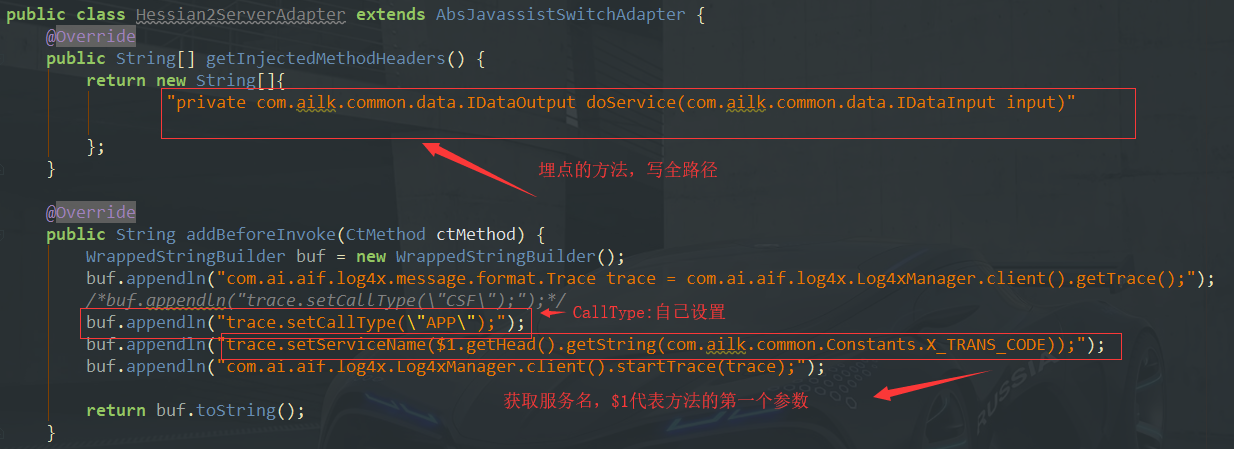
app应用埋点
首先需要到http://git.wadecn.com:18082/wade-root.git上下载埋点的示例代码,比如给WADE框架里的`Hessian2Server.java`的`doService()`方法埋点获取调用服务名的链。
埋点规则
1 2 3
| 1. 适配器的包路径必须以: com.ai.aif.log4x.agent.trans.adapter.impl 开头。 2. com.ai.aif.log4x.agent.trans.adapter.impl 后续路径作为tag标识,配置于log4x-agent.json。 3. 适配器类名的命名规则: 被埋点的类 + "Adapter"
|
埋点示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
| public class Hessian2ServerAdapter extends AbsJavassistSwitchAdapter { @Override public String[] getInjectedMethodHeaders() { return new String[]{ "private com.ailk.common.data.IDataOutput doService(com.ailk.common.data.IDataInput input)" }; } @Override public String addBeforeInvoke(CtMethod ctMethod) { WrappedStringBuilder buf = new WrappedStringBuilder(); buf.appendln("com.ai.aif.log4x.message.format.Trace trace = com.ai.aif.log4x.Log4xManager.client().getTrace();"); buf.appendln("trace.setCallType(\"APP\");"); buf.appendln("trace.setServiceName($1.getHead().getString(com.ailk.common.Constants.X_TRANS_CODE));"); buf.appendln("com.ai.aif.log4x.Log4xManager.client().startTrace(trace);"); return buf.toString(); } @Override public String addAfterInvoke(CtMethod ctMethod, String retType, String retName) { WrappedStringBuilder buf = new WrappedStringBuilder(); buf.appendln("com.ai.aif.log4x.Log4xManager.client().finishTrace(true);"); return buf.toString(); } @Override public String addInExceptionCatch(CtMethod ctMethod, String exName, String exValue) { WrappedStringBuilder buf = new WrappedStringBuilder(); buf.appendln("trace.setRetCode(\"-1\");"); buf.appendln("trace.setRetMsg(\"failed\");"); buf.appendln("trace.setThrowable(" + exValue + ");"); buf.appendln("com.ai.aif.log4x.Log4xManager.client().finishTrace(false);"); return buf.toString(); } }
|
埋点要点
埋点要点
这里解释下获取怎么服务名:我们翻开Hessian2Server.doService():
1 2 3 4 5 6 7
| private IDataOutput doService(IDataInput input) { ... IData head = input.getHead(); ... String serviceName = head.getString(Constants.X_TRANS_CODE); ... }
|
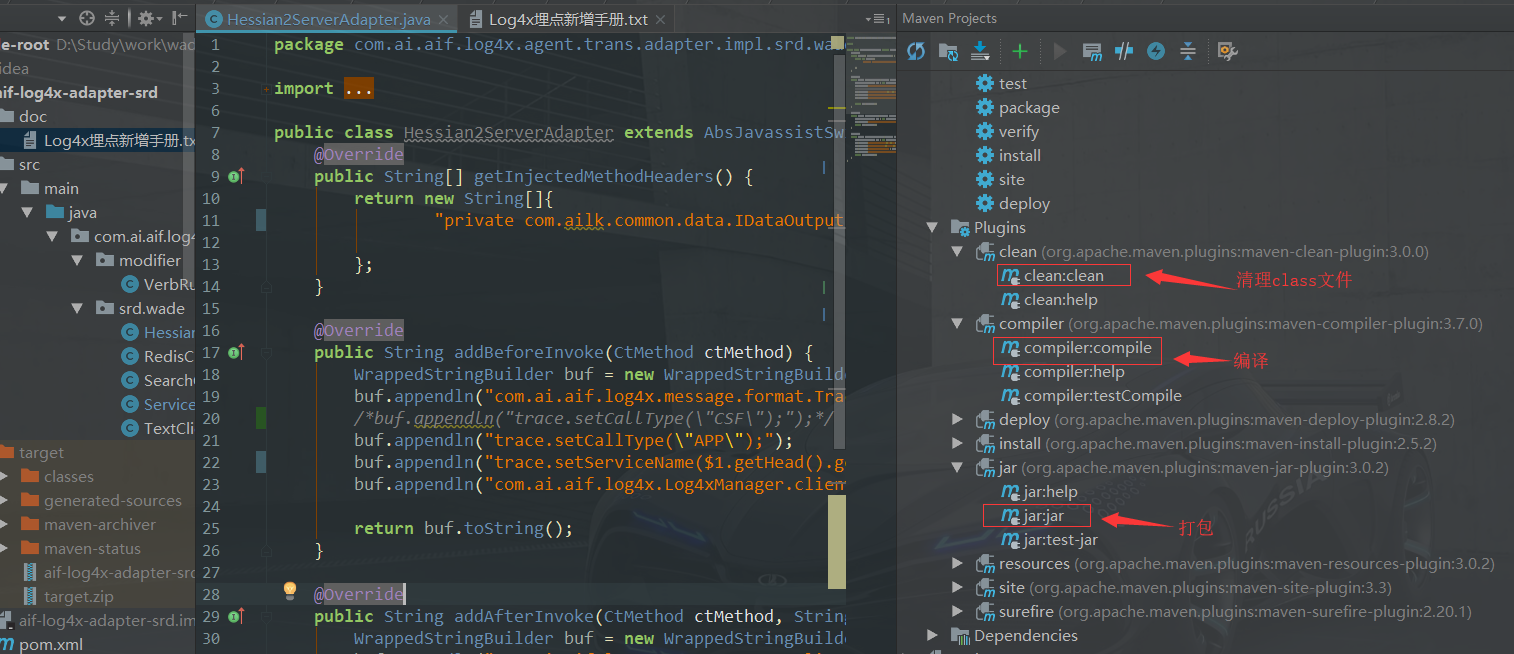
这里获取服务名需要用到方法的第一个参数input,所以使用$1。编译打包。
埋点打包
log4x-agent.json文件配置
app用户下,路径:/home/app/support/agent/log4x-agent.json,添加埋点的路径。
log4x-agent.json文件配置
然后就可以发布APP了
中间件部署
版本要求
1 2 3
| hadoop:2.8.4 jstorm:2.2.1 zookeeper:3.4.8 hbase :1.2.6.1 es :5.6.9 kafka :0.9.0.1 tomcat:7.0.91
|
这里版本一定要一致,不然会出现很多问题,如:es版本导致log4x界面图表不能显示,SQL无法统计;zk版本问题导致JStorm无法连接上zk,JStorm版本问题导致数据进不了es等等。
软件安装目录
log4x安装目录
如上图:bin目录下面的脚本为中间件的启停脚本,data目录下存放个中间件数据,logs目录下存放日志,support目录存放安装的中间件。
support目录
中间件目录
es2.4.1这里弃用。下面讲讲各软件的部署。我们根据数据传输顺序讲解
JDK部署
jdk解压目录如下:
jdk目录
.bash_profile文件修改
环境变量文件
Kafka部署
文件目录
kafka目录如下:
kafka目录
配置server.properties
这里也只需要修改配置文件 vi ~/support/kafka/server.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| ############################# Socket Server Settings ############################# # The port the socket server listens on broker.id=1 port=9092 # Hostname the broker will bind to. If not set, the server will bind to all interfaces host.name=10.242.219.49 #advertised.host.name=10.173.245.214 #advertised.port=9092 ... ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files log.dirs=/home/log4x/logs/kafka num.partitions=1 ... ############################# Zookeeper ############################# zookeeper.connect=10.242.219.49/kafka # Timeout in ms for connecting to zookeeper ...
|
启动进程与数据展示
执行/home/log4x/bin/start-kafka.sh即可启动kafka。这里就会自动创建好我们之前在log4x.yaml里面配置的topic。比如我们想查询APP的callType。查询语句如下:
1
| ./kafka-console-consumer.sh --zookeeper 10.242.219.49:2181/kafka --from-beginning --topic LOG4X-TRACE-TOPIC | grep '"callType":"APP"'
|
就会返还数据:
kafka消费者数据查询
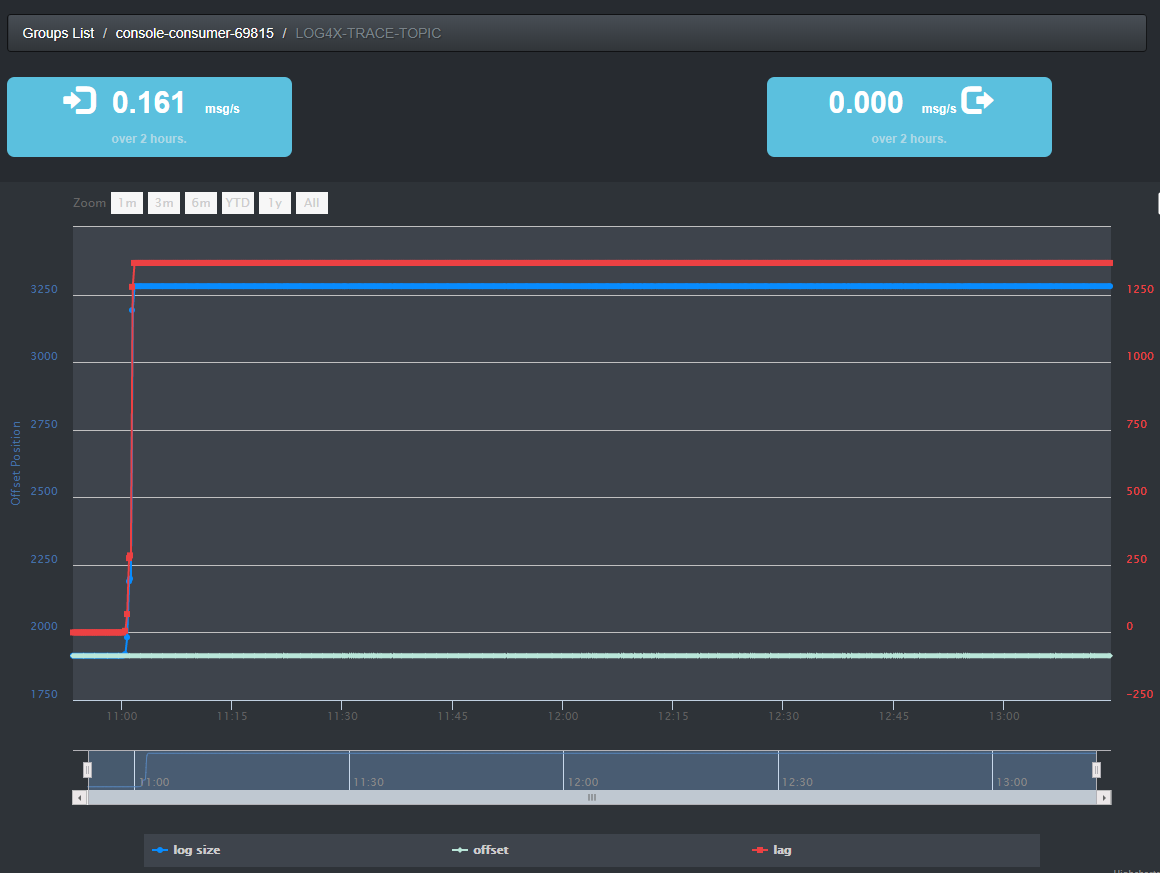
也可以打开Kafka Consumer Offset Monitor的web监控界面:
kafka的web监控
如上图,显示随时间数据的消费曲线。
JStorm部署
文件目录
Jstorm目录如下:
JStorm目录
这里这个log4x目录需要自己创建,把log4x开发好的log4x-jstorm-3.0.0.jar放入~/support/jstorm/log4x/lib/下,用于jstorm拓扑启动worker时加载。
配置.bash_profile
添加环境变量
1 2
| vi ~/.bash_profile export JSTORM_HOME=/home/log4x/support/jstorm
|
配置storm.yaml
这里需要修改配置文件~/support/jstorm/conf,storm.yaml文件:
1 2 3 4 5 6 7 8 9 10 11 12
| storm.zookeeper.servers: - "10.242.219.49" storm.zookeeper.port: 2281 storm.zookeeper.root: "/jstorm" nimbus.host: 10.242.219.49 cluster.name: "log4x-storm-cluster" storm.local.dir: "/home/log4x/data/jstorm/data" jstorm.log.dir: "/home/log4x/logs/jstorm" ...
|
配置log4x.jstorm.yaml
此外还需要修改log4x.jstorm.yaml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115
| ... jdbc.driver: "com.mysql.jdbc.Driver" jdbc.url: "jdbc:mysql://10.242.219.49:3306/log4x?allowMultiQueries=true&useSSL=false" jdbc.username: "root" jdbc.password: "root" ... zookeeper: server.list: "10.242.219.49:2181" base.path: "/log4x" ... hbase: flush.period.ms: 10000 default: namespace: "cx_log4x" ttl: 86400 zookeeper: server.list: "10.242.219.49:2181" ... kafka: broker.zk.path: "/kafka/brokers" consumer.zk.root: "/log4x/consumer" default: zookeeper: server.list: "10.242.219.49:2181" ... topic: "LOG4X-MSG-TOPIC" trace: topic: "LOG4X-TRACE-TOPIC" log: topic: "LOG4X-LOG-TOPIC" metric: topic: "LOG4X-METRIC-TOPIC" filters: - object: "AggregateBolt" rules: - callType: "CSF,CSFClient,EJBCall,EJBProcess" ps: "true" - object: "TraceESBolt" rules: - callType: "CSF,JDBC" ps: "true" trace.mapping: CEN: callType: "CSF,CSFClient,EJBCall" ps: "true" CHL: callType: "CSF,CSFClient,EJBCall" ps: "true" appName: callType: "CSF" ... alarm.window.step: 60 ... elasticsearch: default: cluster.name: "test185" cluster.hosts: "10.242.219.49:9200" ... shards: 2 replicas: 0 ... ... storm: worker.num: 1 package: "com.ai.aif.log4x.jstorm.storm" topology: component: - "TraceJsonSpout-1[2]" - "AggregateBolt-1[3]" - "TraceJsonSpout-2[2]" - "TraceESBolt-1[3]" - "MonitorBolt-1[1]" ... ...
|
这个文件里需要连接的有:MySQL、kafka、HBase、Zookeeper、ElsaticSearch。三个点为为省略的内容。
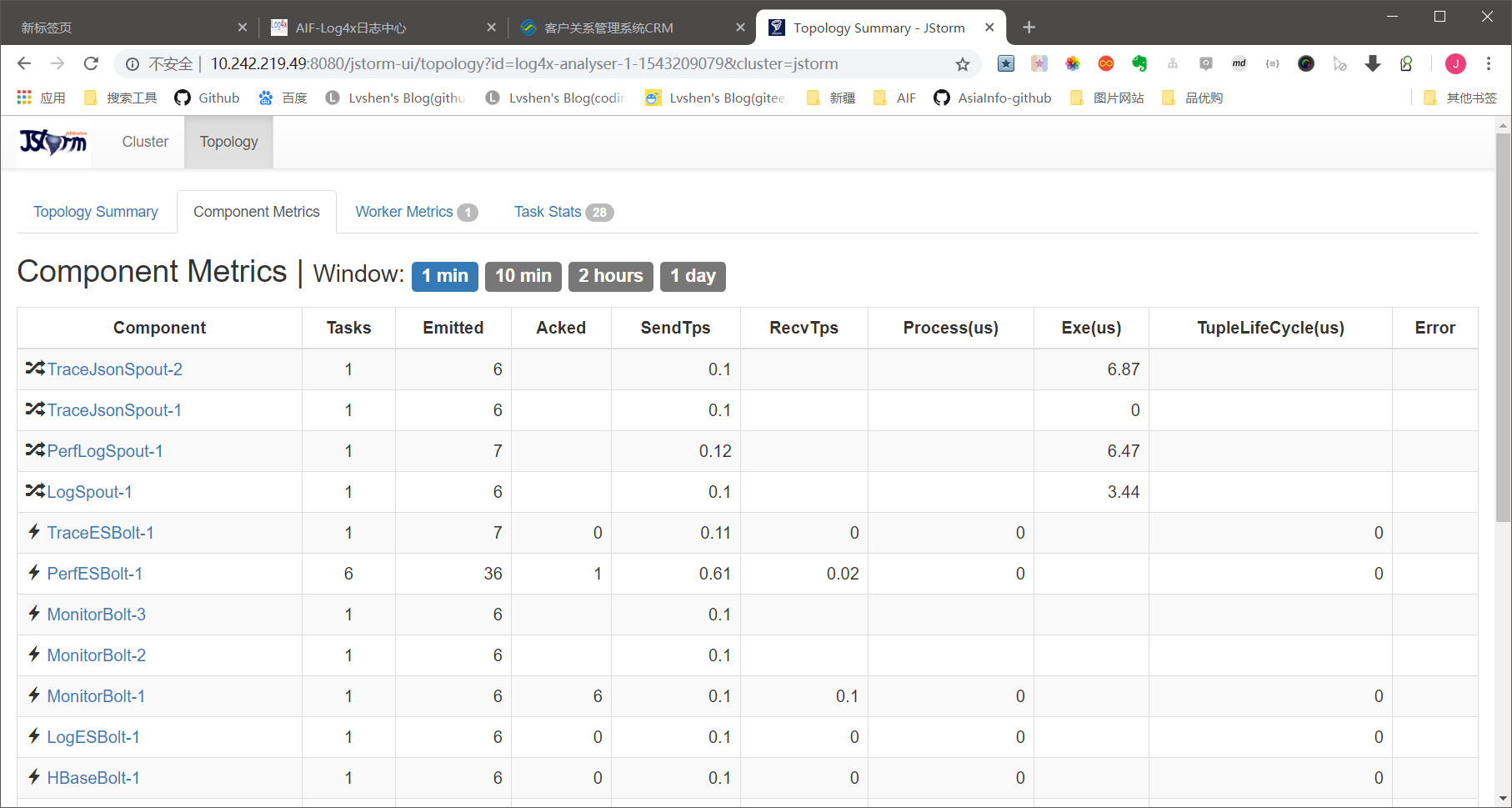
启动进程
进入~/bin下就可以启动start-jstorm-nimbus.sh,start-jstorm-supervisor.sh,start-jstorm-topology.sh。
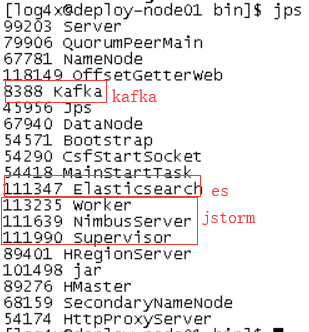
我们jps命令监控进程:
jstorm进程
安装JStormUI
先执行命令:
1 2
| mkdir ~/.jstorm cp ~/support/jstorm/conf/storm.yaml ~/.jstorm
|
然后将JStormUI的war包放入tomcat,即可在界面访问。
JStormUI
HBase部署
文件目录
HBase目录如下:
HBase目录
配置hbase-site.xml
vi ~/support/hbase/conf/hbase-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| <configuration> <property> <name>hbase.rootdir</name> <value>file:///home/log4x/data/hbase</value> </property> <property> <name>hbase.cluster.distrubuted</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>10.174.26.145</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>hbase.tmp.dir</name> <value>/home/log4x/logs/hbase/tmp</value> </property> </configuration>
|
配置hbase-env.sh
vi ~/support/hbase/conf/hbase-env.sh
1
| export HBASE_MANAGES_ZK=false
|
进程启动与数据展示
执行~/support/hbase/bin/start-hbase.sh。
jps查看
HBase进程
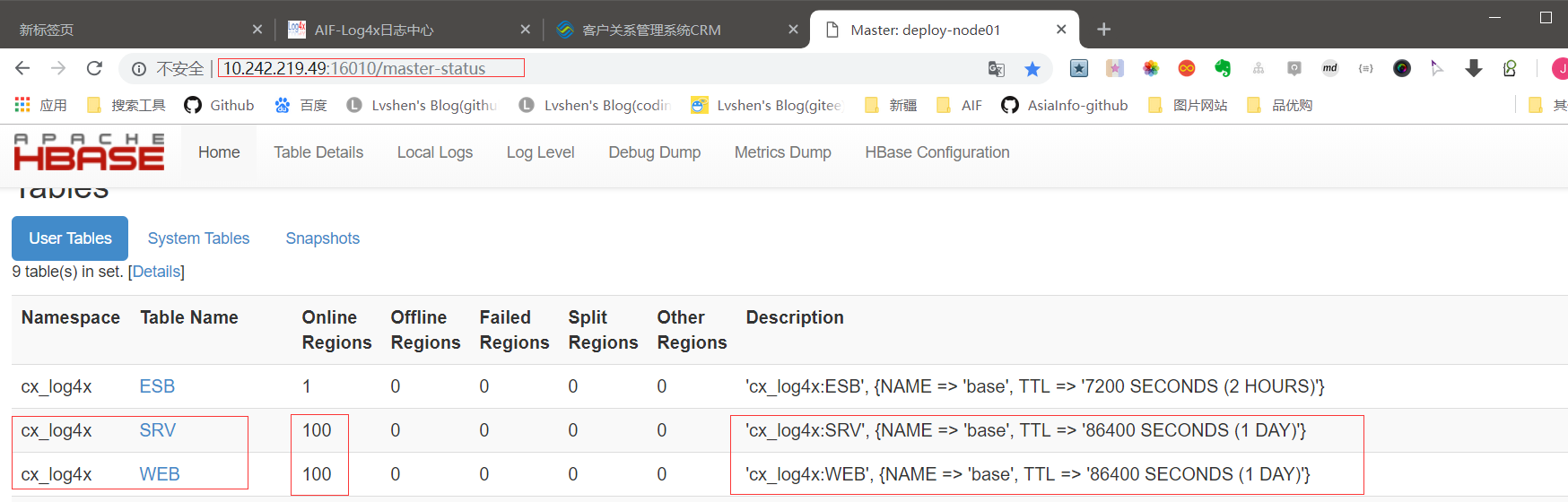
执行~/support/hbase/bin/hbase shell进入数据库,我们可以看到程序已建好的表:
Hbase表.png
web页面也能看到:
hbase的web界面
这里需要提前创立表空间:cx_log4x
hbase常用命令(需要进入hbase shell):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| #hbase创建表空间 create_namespace 'cx_log4x' #列出表明 >list #统计表的记录条数 > count 'cx_log4x:WEB' #查看表的数据,使用指定的时间范围和返回10条。 > scan 'cx_log4x:SRV', {LIMIT=>10,TIMERANGE=>[1495953605000,1496385605000]} #创建表,base指列名,TTL是数据存活时间,单位秒。 > create 'cx_log4x:ESB', {NAME => 'base',VERSIONS => 1, TTL => 7200, COMPRESSION => 'NONE'} #清空表,清空表数据。 > truncate 'cx_log4x:WEB
|
Hadoop部署
如果hbase需要用到分布式文件系统HDFS作为存储,这里就需要部署hadoop。
文件目录
hadoop目录如下:
hadoop目录
配置core-site.xml
修改配置文件:vi ~/support/hadoop/etc/hadoop/core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://10.242.219.49:9000</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>10.242.219.49:2181</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/log4x/logs/hadoop/tmp</value> </property> </configuration>
|
配置hdfs-site.xml
vi ~/support/hadoop/etc/hadoop/hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/log4x/data/hadoop/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/log4x/data/hadoop/datanode</value> </property> </configuration>
|
启动进程
启动之前,需要格式化文件系统
1 2 3 4 5 6 7 8 9
| cd ~/support/hadoop/bin ./hadoop namenode -format ./hadoop fs -mkdir /hbase ./hadoop fs -chmod 777 /hbase ./hadoop fs -ls / #下面为显示的结果 Found 1 items drwxrwxrwx - log4x supergroup 0 2018-10-24 12:02 /hbase
|
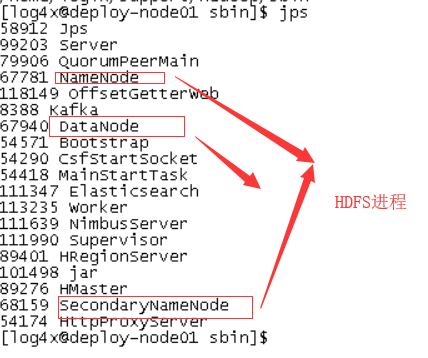
启动HDFS:~/support/hadoop/sbin/start-dfs.sh。
jps命令查看进程:
HDFS进程
Elasticsearch部署
文件目录
es解压后的目录如下:
es目录
配置elasticsearch.yml
这里只需要修改配置文件elasticsearch.yml
vi /home/log4x/support/elasticsearch/config/elasticsearch.yml
1 2 3 4 5 6 7 8 9
| node.name: log4x-escluster path.data: /home/log4x/data/es path.logs: /home/log4x/logs/es ... network.host: 10.242.219.49 http.port: 9200 ... discovery.zen.ping.unicast.hosts: ["10.242.219.49"]
|
启动进程与数据展示
执行/home/log4x/bin/start.es启动es
在Chrome浏览器上安装elasticsearch-head插件,就能图形化显示es的内容:
es索引显示
如图,显示了几个索引,索引里面的数据需要通过kafka输送过来
es数据展示
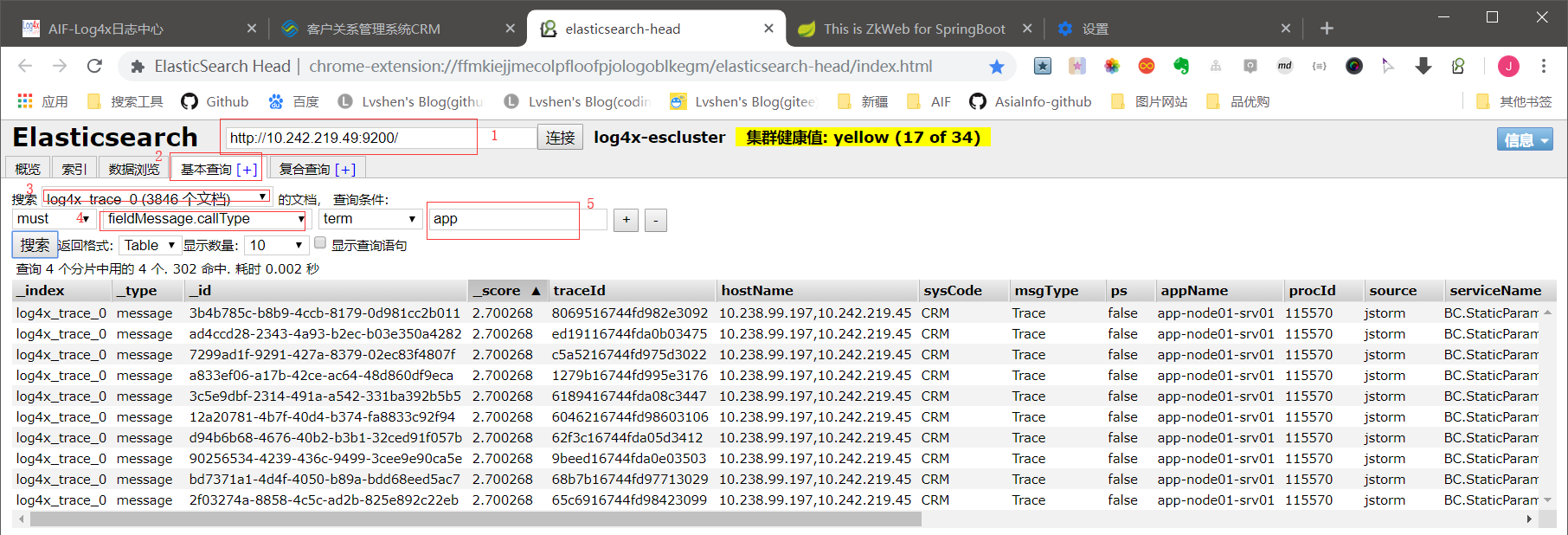
之前我们埋点设置了APP类型的callType,只要kafka启动,jstorm启动,es里面就有APP类型的数据,查询步骤见上图。
Zookeeper部署
创建myid
首先在~/support/data/zk/下创建文件myid,里面写入1。
文件目录
目录如下:
zk目录
配置zoo.cfg
修改配置文件:vi ~/support/zk/etc/zoo.cfg
1 2 3 4 5 6 7 8 9
| ... dataDir=/home/log4x/data/zk ... clientPort=2181 minSessionTimeout=5000 maxSessionTimeout=10000 server.1=10.242.219.49:28880:38880
|
进程启动
执行脚本 ~/bin/start-zk.sh
web界面查看(自己部署的zkweb监控)
zkweb界面
之前注册到zk的中间都有显示:jstorm,log4x,hbase,kafka
LOG4X-WEB部署
文件目录
主目录如下:
log4x-web主目录
其中bin目录放的启停脚本,deploy下方的log4x-web文件,support目录下面放的csfproxy,csfserver,tomcat
配置tomcat
由于文件放在tomcat外面,需要配置vi ~/support/log4xweb/support/tomcat/conf/server.xml
tomcat配置
还要修改log4x-web的服务地址。vi ~/support/log4xweb/deploy/log4x-web/WEB-INF/classes/config.properties
1 2
| service_http_ip=10.242.219.49 service_http_port=12222
|
配置csfproxy
vi ~/support/log4xweb/support/csfproxy/configext/log4x.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| ... ## file|kafka|msgFrame msg.sender=kafka msg.sender.trace.topic=CRM-TRACE-TOPIC msg.sender.log.topic=CRM-LOG-TOPIC msg.sender.batch.size=1 ## Kafka settings kafka.metadata.broker.list=10.242.219.49:9092 ... ## logfile settings, if msg.sender=file msg.logfile.dir=/home/log4x/support/log4xweb/logs/csfproxy msg.logfile.maxFileSize=100 ...
|
配置csfserver
修改log4x-service.yaml
vi ~/support/log4xweb/support/csfserver/configext/log4x-service.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
| db: ... jdbc.driver: com.mysql.jdbc.Driver jdbc.url: jdbc:mysql://10.242.219.49:3306/log4x?allowMultiQueries=true&useUnicode=true&characterEncoding=utf-8&autoReconnect=true jdbc.username: root jdbc.password: root ... hbase: hbase.row.max: 500 hbase.namespace: cx_log4x hbase.zookeeper: 10.242.219.49:2181 hbase.zookeeper.client: hbase es: cluster: - es.cluster.name: log4x es.url: http://10.242.219.49:9200 ... index.group: - topic: log4x_log cluster: log4x - topic: log4x_perf cluster: log4x - topic: log4x_trace cluster: log4x - topic: log4x_dict_spec_sql cluster: log4x ... task: - task.name: serviceSync task.open: true task.cron: "0/30 * * * * ?" ...
|
修改csf.xml
vi ~/support/log4xweb/support/csfserver/configext/csf/csf.xml
1 2 3 4 5 6 7 8 9 10 11 12 13
| <?xml version="1.0" encoding="UTF-8"?> <Csf> <Category name="client" description="客户端运行引擎需要的配置"> ... <Item name="zk.server.list"> <value>10.242.219.49:2181</value> <description>多个地址用逗号(,)隔开 </description> </Item> ... </Category> ... </Csf>
|
修改defaults.xml
vi ~/support/log4xweb/support/csfserver/configext/system/service/defaults.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| <defaults> ... <datasource> <clazz name="com.ai.appframe2.complex.datasource.impl.LocalMutilDataSourceImpl"> <property name="tableName" value="cfg_db_acct" /> </clazz> <pool name="base" primary="true" type="SELF"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://10.242.219.49:3306/log4x" /> <property name="username" value="root" /> <property name="password" value="root" /> ... ... </datasource> </defaults>
|
启动脚本
cd ~/support/log4xweb/bin,依次启动:
1 2 3 4
| ./start-csfproxy.sh ./start-csfserver.sh ./start-task.sh ./star-tomcat.sh
|
MySQL部署
初始化配置
上面的应用需要用到MySQL数据库,这里讲讲怎么离线部署MySQL数据库。将下载好的mysql-5.7.23-linux-glibc2.12-x86_64.tar.gz解压。目录如下:
mysql目录
这里需要创建my.cnf文件。里面需要修改的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
| [client] default-character-set=utf8 [mysqld] datadir=/home/log4x/support/mysql socket=/home/log4x/data/mysql user=mysql port=3306 bind-address=0.0.0.0 lower_case_table_names=1 symbolic-links=0 character-set-server=utf8 init_connect='SET NAMES utf8' [mysql] no-auto-rehash default-character-set=utf8 [mysqld_safe] log-error=/home/log4x/logs/mysql/mysqld.log pid-file=/home/log4x/support/mysql/mysqld.pid sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES log_timestamps=SYSTEM
|
接下来需要安装,命令如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
| #添加环境变量 vi ~/.bash_profile export MYSQL_HOME=/home/log4x/support/mysql PATH=$MYSQL_HOME/bin:$PATH:$HOME/.local/bin:$HOME/bin export PATH #执行安装 ./mysqld --initialize --user=mysql --basedir=/home/log4x/support/mysql/ --datadir=/home/log4x/data/mysql --explicit_defaults_for_timestamp #服务启动(启动成功,会出现mysqld的服务,端口3306) cd ~/support/mysql/bin/ ./mysqld_safe --defaults-file=/home/log4x/support/mysql/my.cnf & #mysql启停 cd ~/support/mysql/bin mysqld_safe& --defaults-file=/app/mysql/mysql/my.cnf & 启动 mysqladmin shutdown -uroot -proot 停 #开始不需要密码登陆 [log4x@deploy bin]$ mysql -uroot -p 【注释,在下面的要求你输入密码的时候,你不用管,直接回车键一敲就过去了】 Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 48 Server version: 5.1.41-log Source distribution Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> use mysql; Database changed #设置密码 mysql>update mysql.user set authentication_string=password('root') where user='root' ; #创建用户 CREATE USER 'log4x'@'%' IDENTIFIED BY 'password'; #创建database CREATE DATABASE 'log4x' #导入数据(举例) source /home/log4x/support/mysql/sql/log4x_sql/mysql/*.sql
|
创建&插入表数据
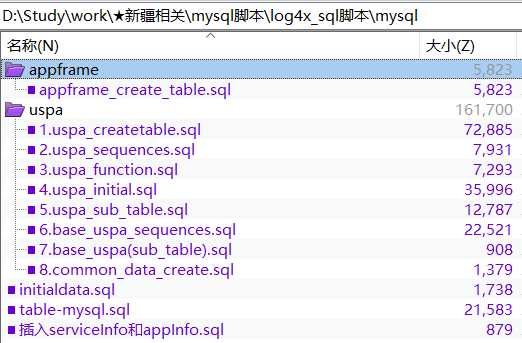
需要插入如下图的表:
mysql脚本
脚本执行顺序:
1 2 3 4
| 1. appframe/appframe_create_table.sql 2. table-mysql.sql 3. uspa/uspa[1-8] 4. initialdata.sql
|
进入mysql客户端:
1 2 3
| mysql -uroot -proot use log4x; show table;
|
mysql表整合
上图画红框的为jstorm创建的表,会以天为单位创建。
实例信息和服务信息的表的配置
应用有多少个中心,首先就应该在l4x_stats_config表里面就要配多少个中心。这里配置多少个中心,对应log4x-web的界面上的首页-服务监控、服务排行榜、服务视图上就展示多少个中心。例如:
1
| INSERT INTO `l4x_stats_config` (`STATS_CONFIG_ID`, `STATS_TYPE_ID`, `STATS_CODE`, `STATS_NAME`, `STATE`, `SYS_CODE`, `STATS_DESC`, `STATS_TYPE_CODE`, `STATS_TYPE_NAME`) VALUES ('2', '1', 'OrderCentre', '订单中心', 'U', 'CRM', '', 'CEN', '中心');
|
log4x提供了一个同步服务信息的功能,会定时将表l4x_svc_cen_XXXX(日期格式为yyyyMMdd)有的,但是l4x_service_info没有记录的服务信息查询出来,然后根据`log4x-service.xml里面serviceSync标签配置的匹配规则,根据serviceCode找到对应的centerCode,然后将这条服务信息插入到l4x_service_info表格中。例如:
1
| INSERT INTO `l4x_service_info` (`SERVICE_INFO_ID`, `SERVICE_NAME`, `SERVICE_CODE`, `CENTER_CODE`, `SERVICE_INFO_DESC`, `STATE`, `SYS_CODE`, `SERVICE_TYPE`) VALUES ('42', 'OrderCentre.person.ISubscriberQuerySV.queryCentreInfo', 'OrderCentre.person.ISubscriberQuerySV.queryCentreInfo', 'OrderCentre', 'OrderCentre.person.ISubscriberQuerySV.queryCentreInfo', 'U', 'CRM', 'DEFAULT');
|
需要对哪些应用实例进行监控,就应该在l4x_app_info表中配置这些实例的信息。在这里配置的实例信息,对应log4x-web的界面上的性能数据监控、实例统计都是可以看的到的,其中APP_NAME对应l4x_app_call_XX的TYPE_CODE字段。一般可以拿建设方案里面的主机配置excel表格导出来,导入到app info表里面去。例如:
1
| INSERT INTO `l4x_app_info` (`APP_ID`, `APP_NAME`, `HOST_NAME`, `HOST_IP`, `CENTER_CODE`, `CENTER_NAME`, `GROUP_NAME`, `SYS_CODE`, `SYS_NAME`) VALUES ('1', 'app-node01-srv01', 'app-node', '10.242.219.45', 'ord', '订单中心', 'app-node01', 'CRM', 'CRM');
|
界面展示
1 2 3
| #log4x 页面访问地址 http://10.242.219.49:8080/log4x-web/home admin/log4x123!@#
|
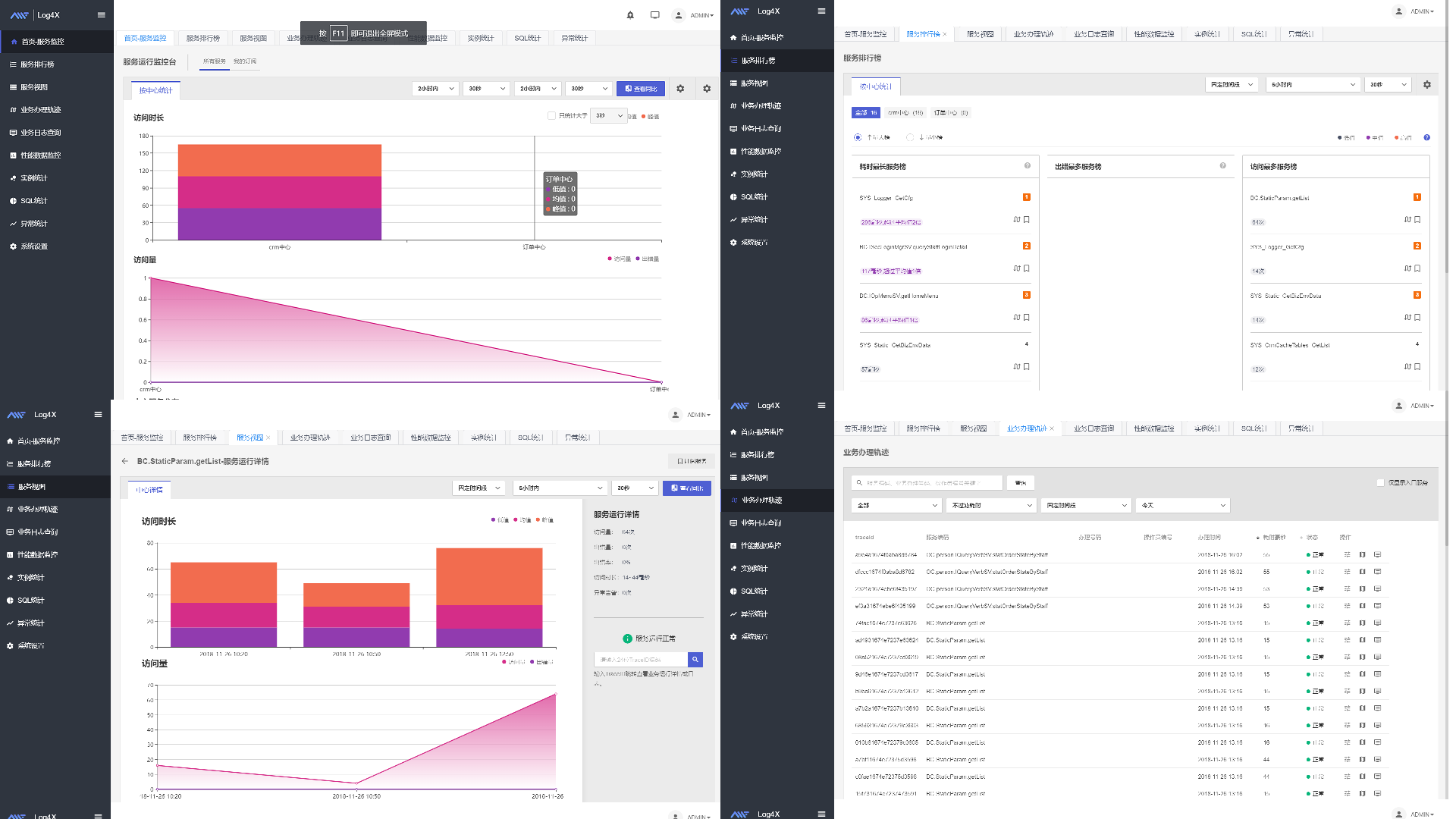
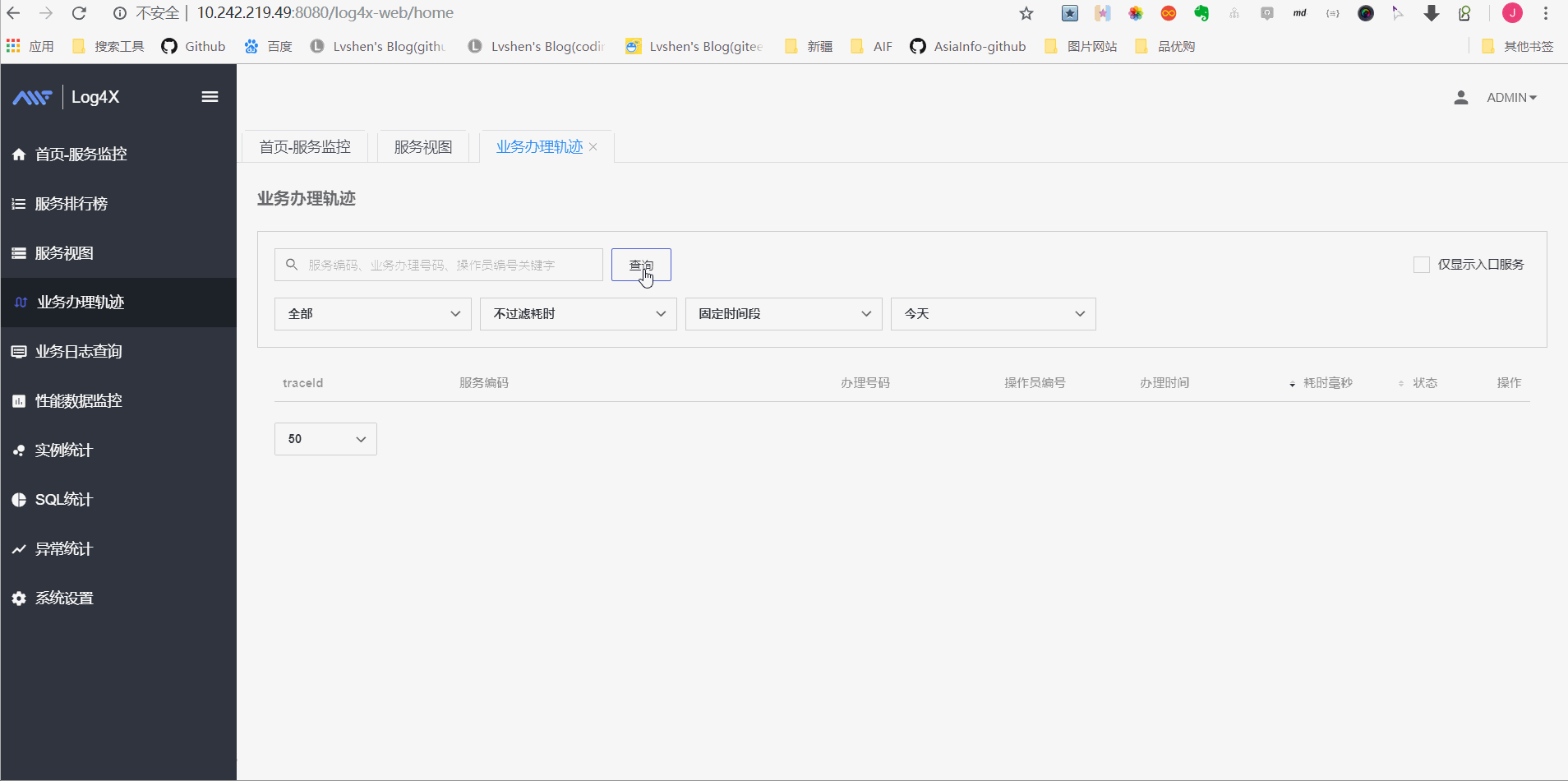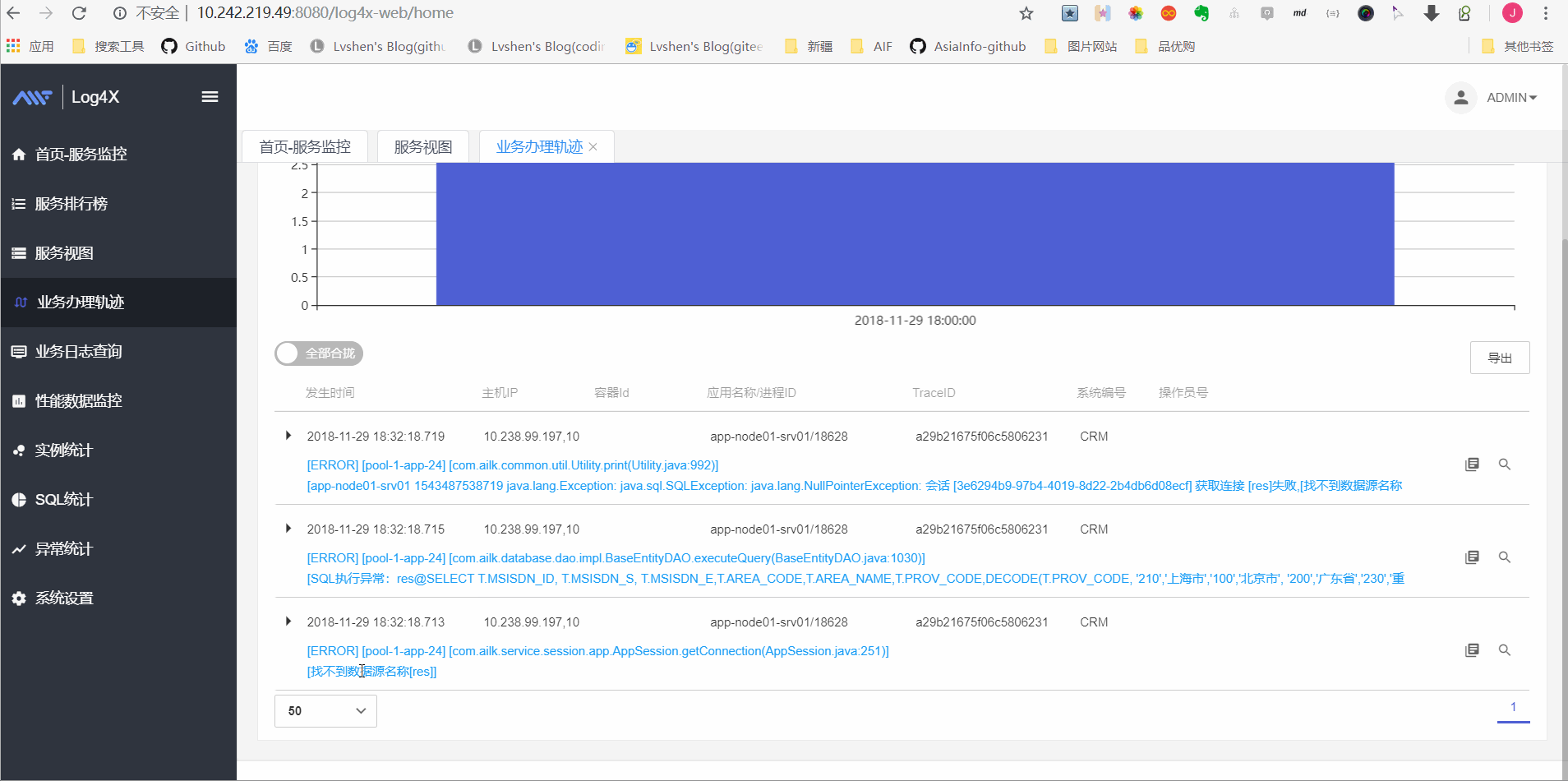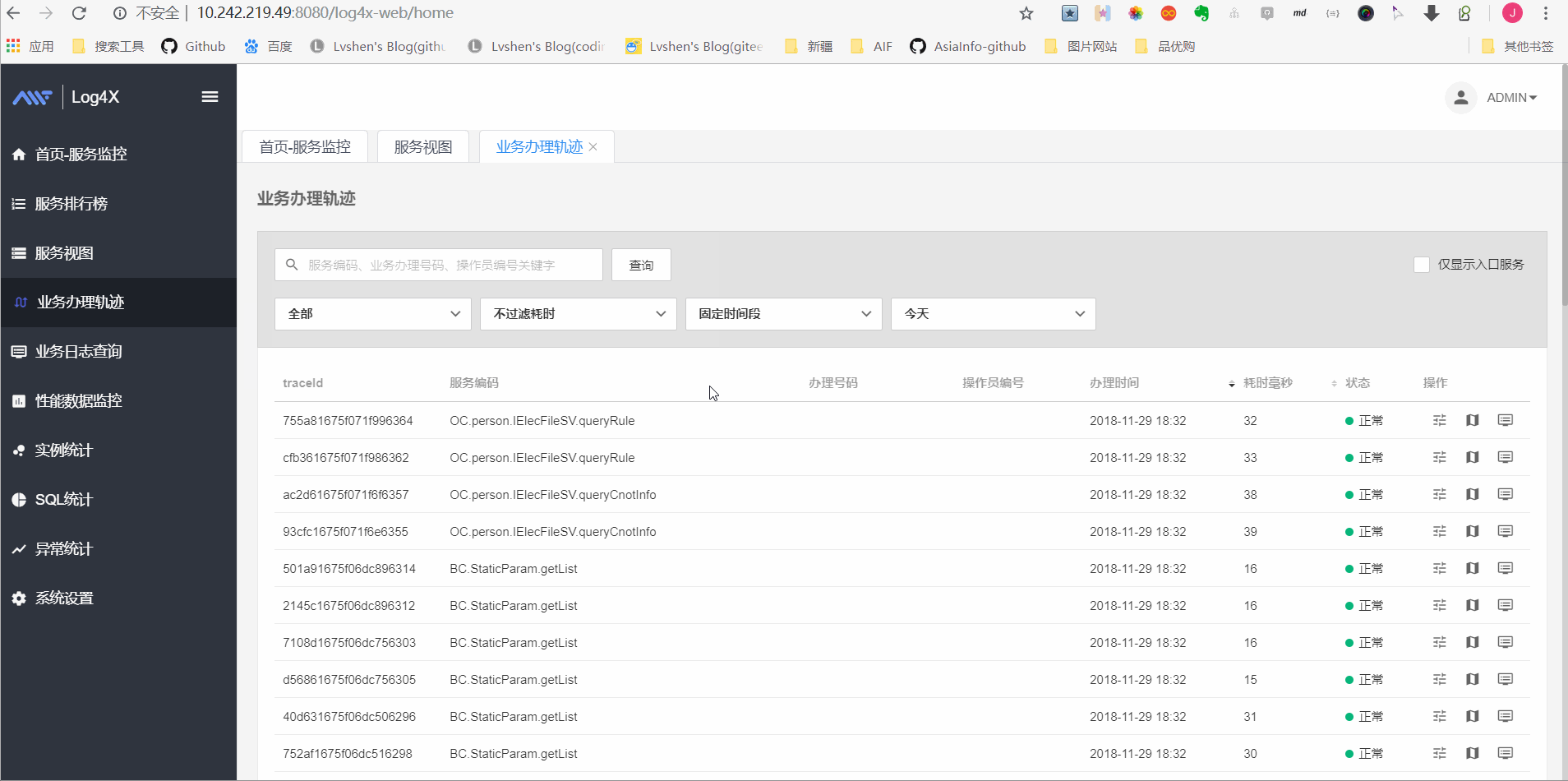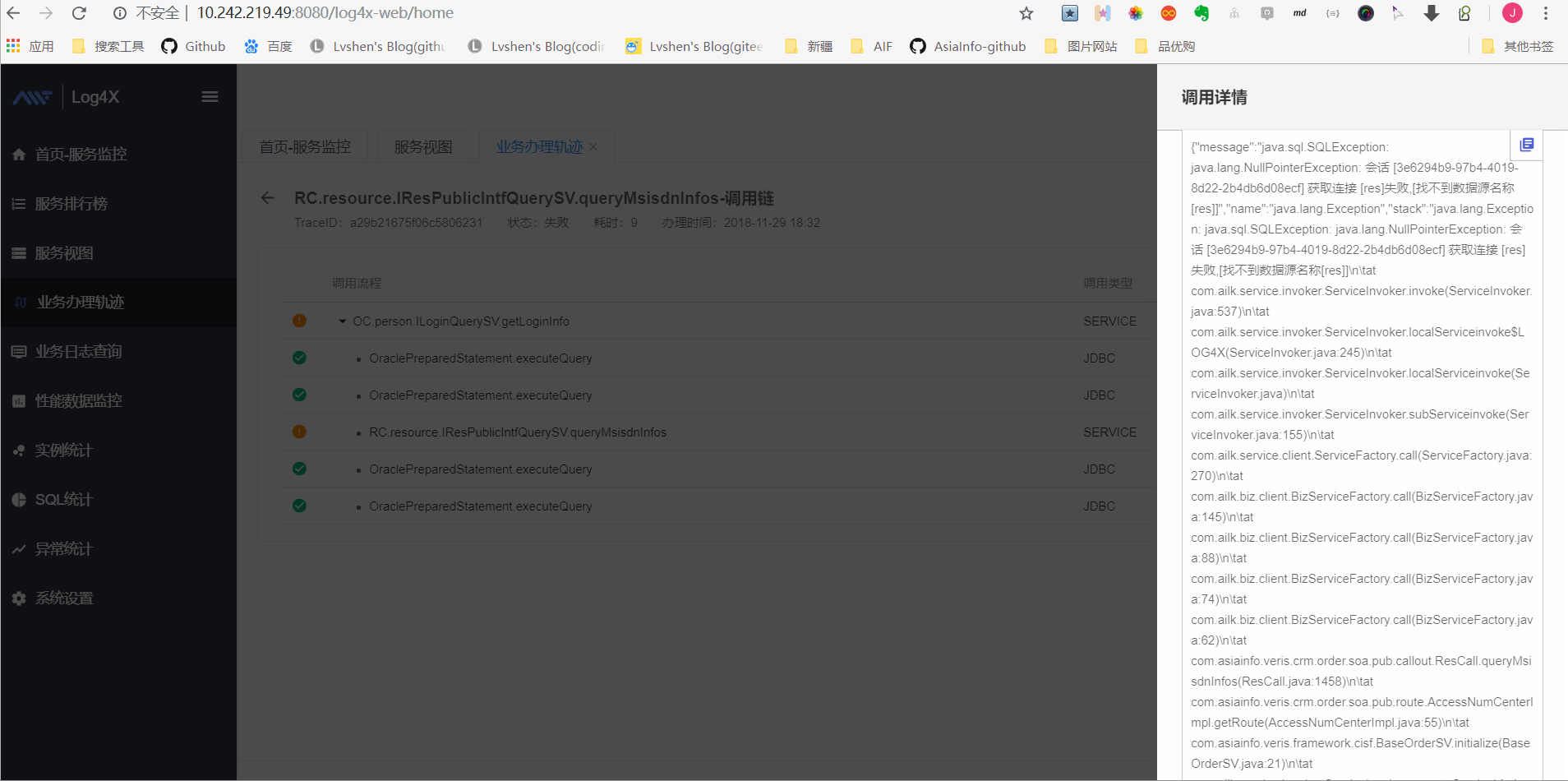
业务办理轨迹查询
如图显示调用链情况:
调用链显示情况
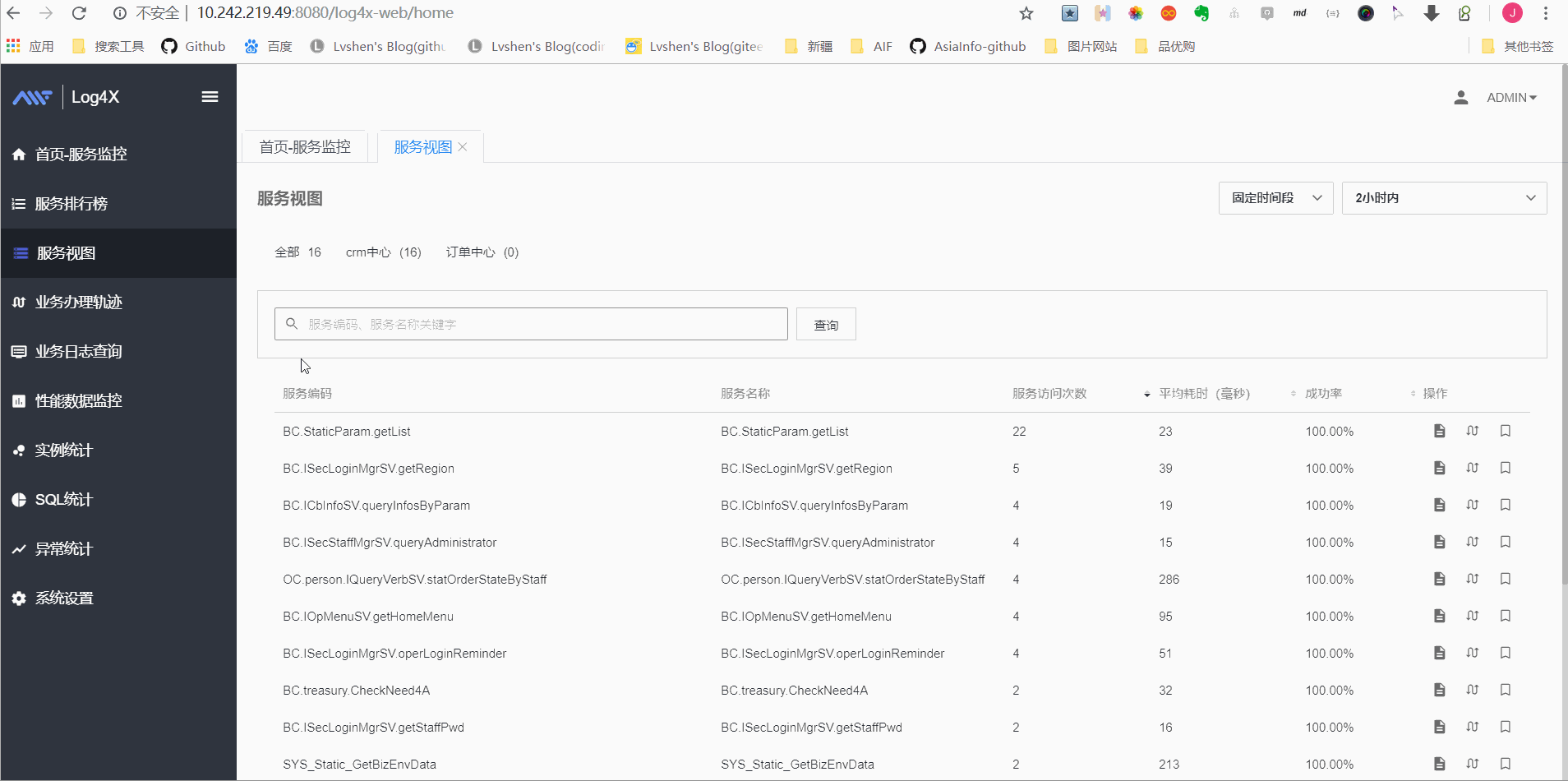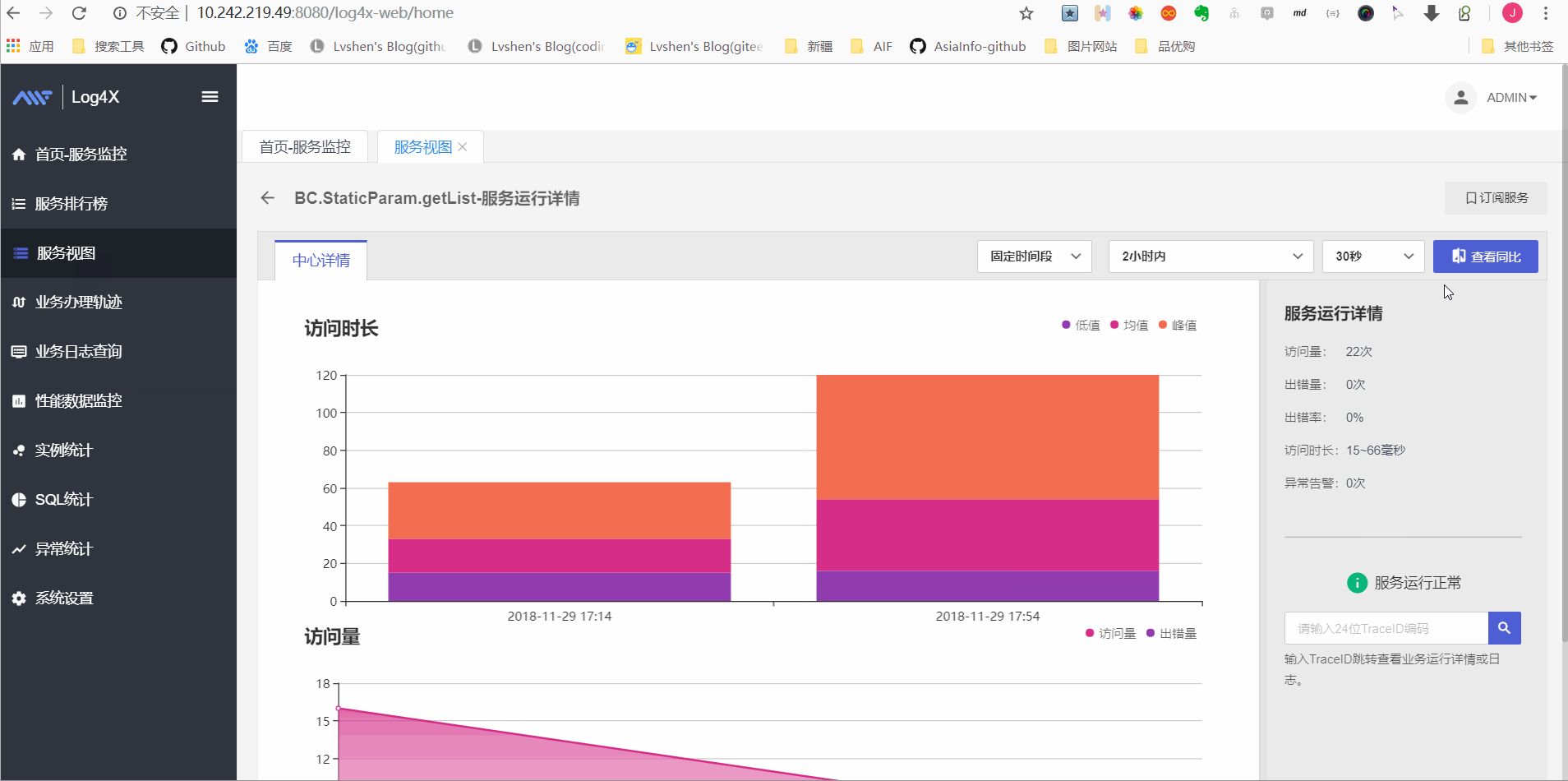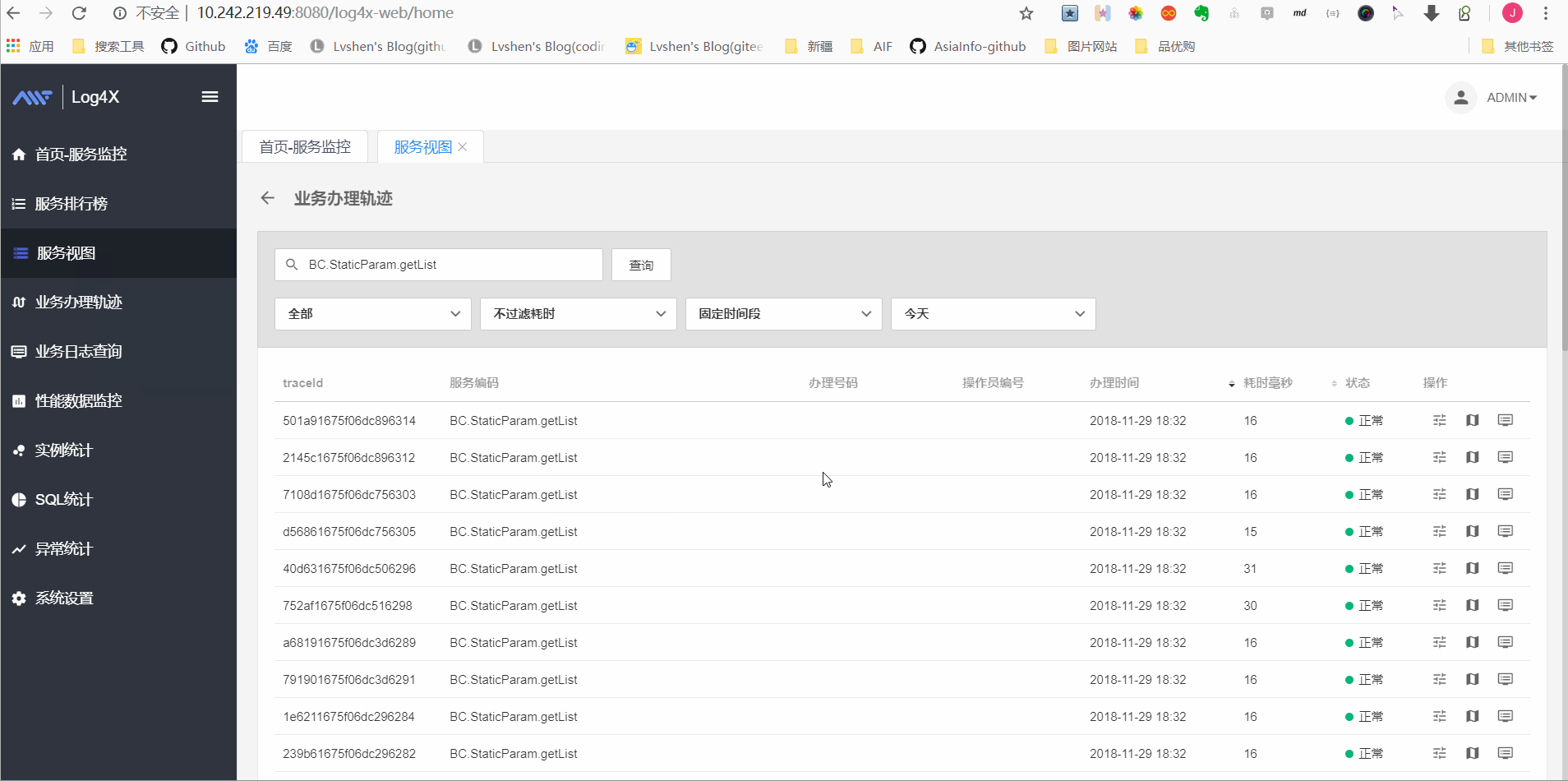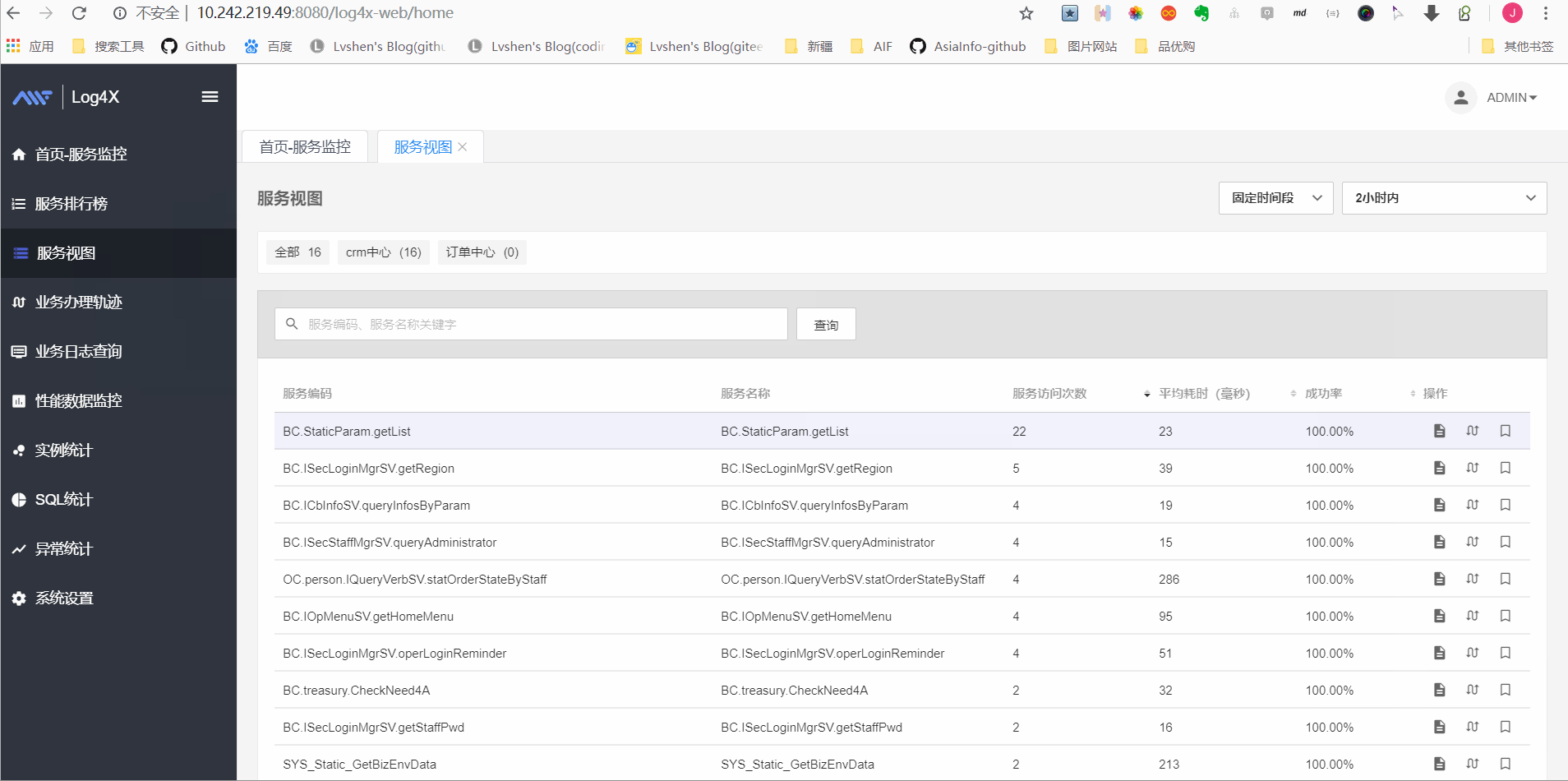
服务视图
服务运行详情
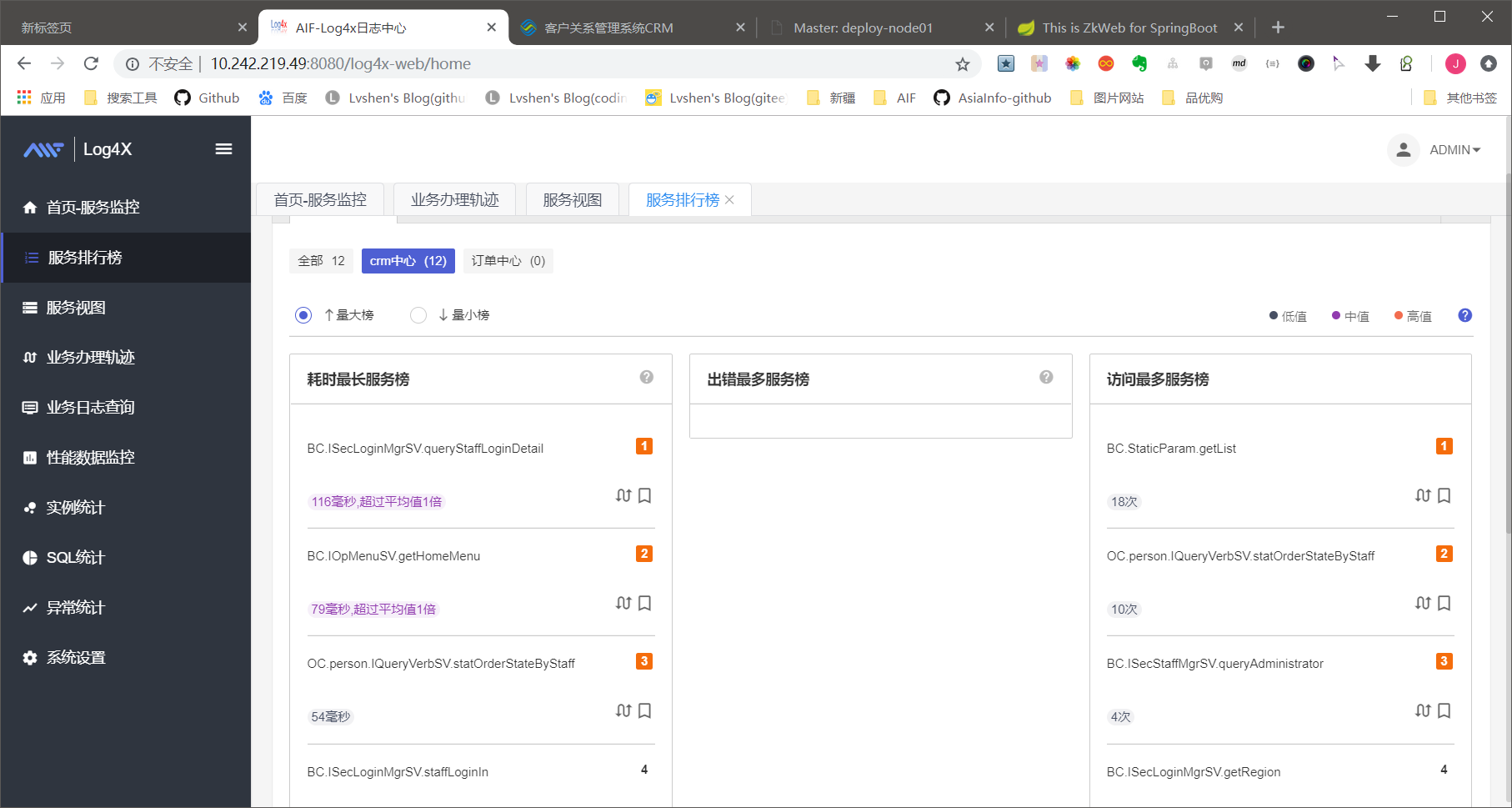
服务排行榜
服务排行榜
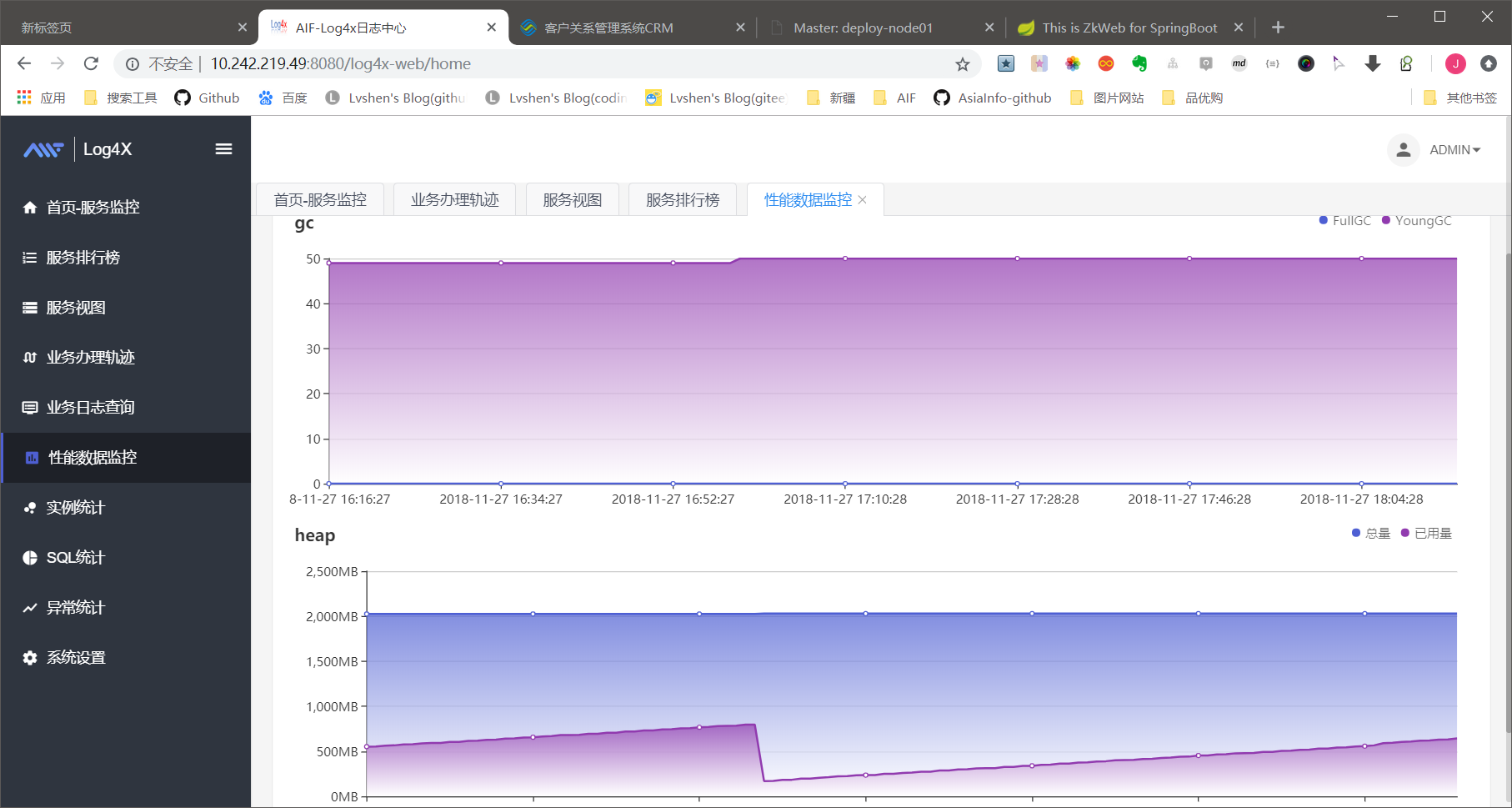
性能数据监控
性能数据监控
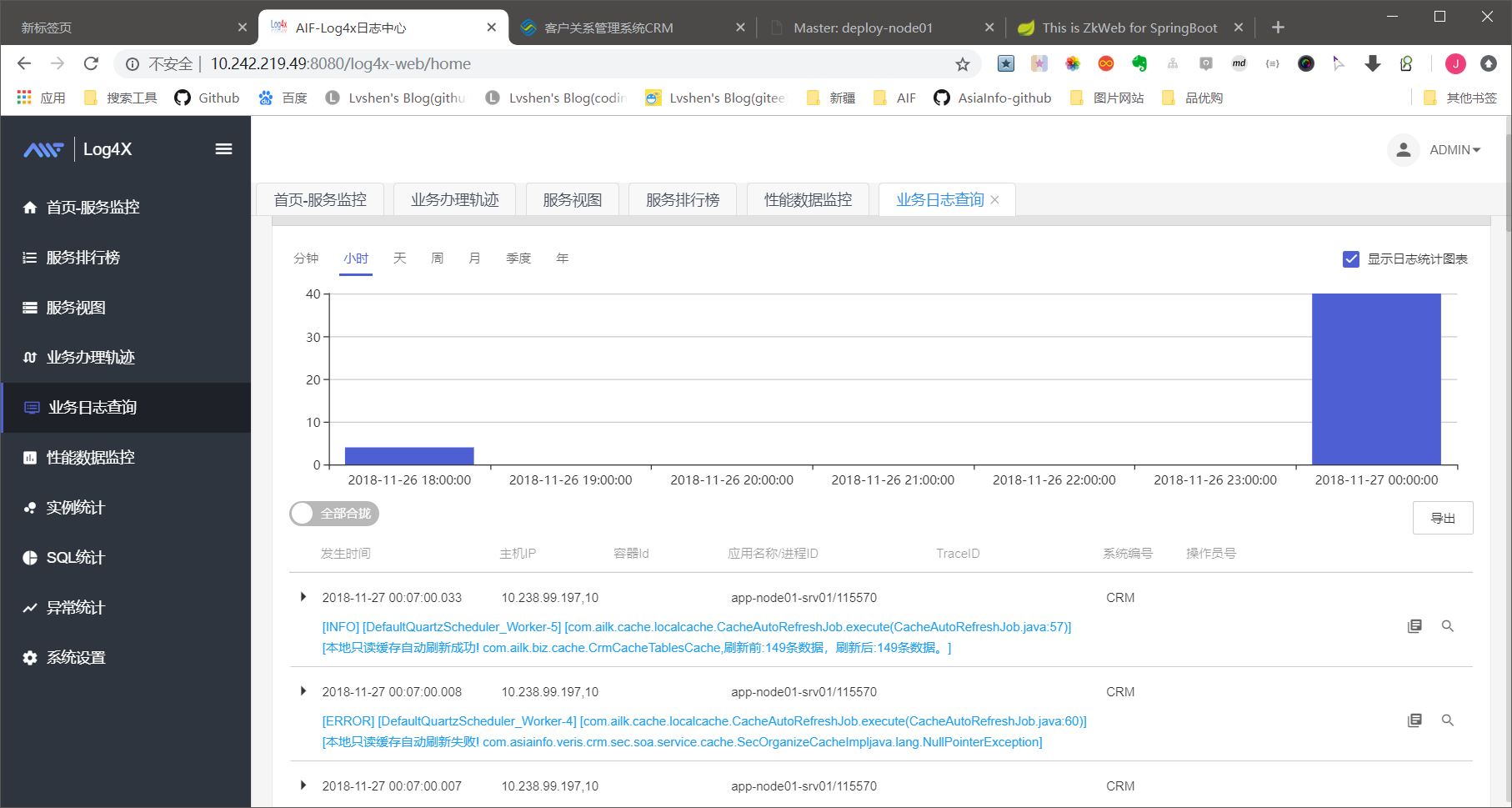
日志查询
日志监控
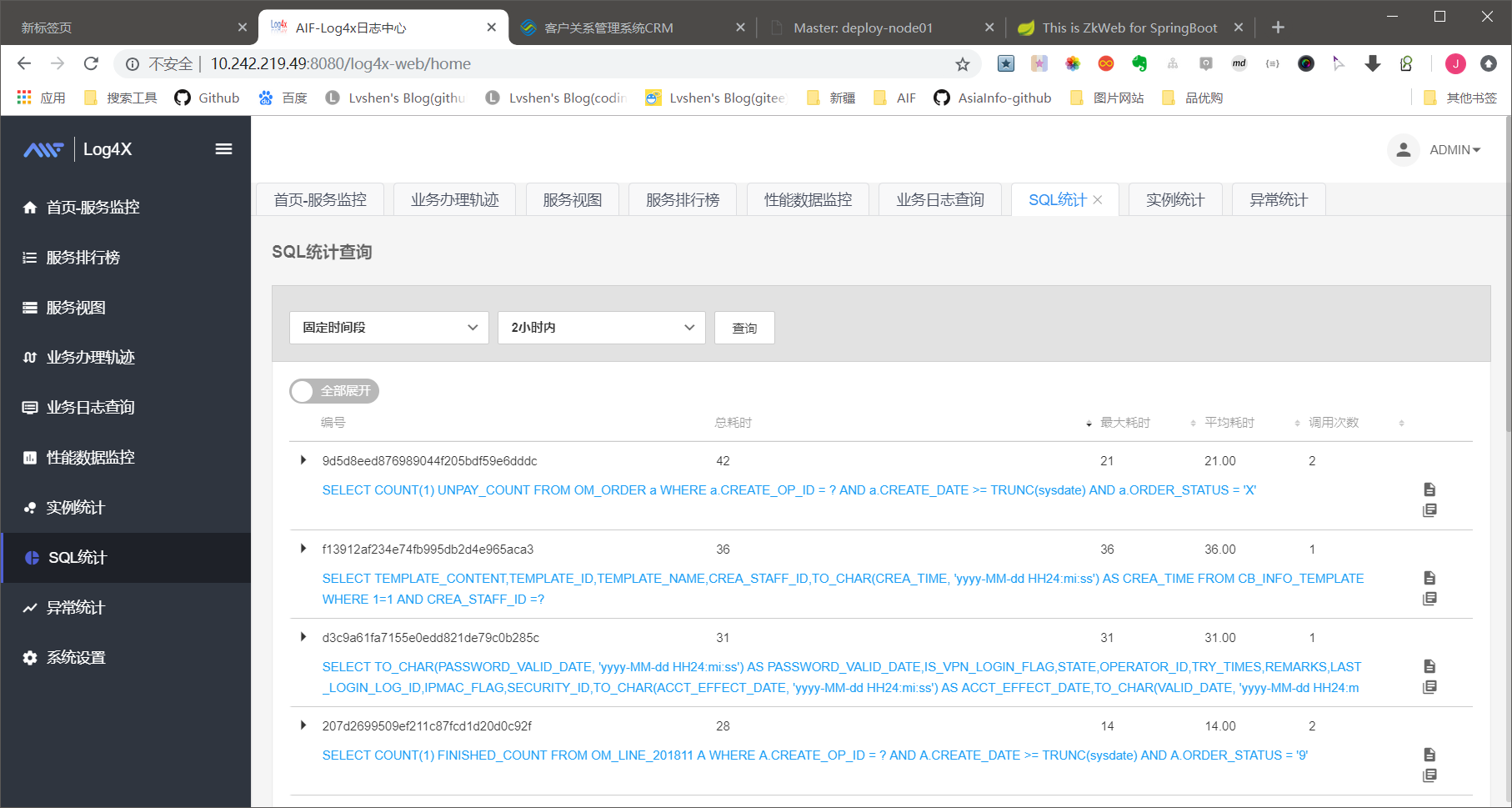
SQL统计
sql统计