快速排序
快速排序是一种比选择排序更优秀的排序算法,选择排序运行的时间为:$O(n^2)$,而快速排序法的运行时间为:$O(nlog_2n)$,快速排序使用了D&C的思想(一种分而治之的思想)。下面我们来分析快速排序算法。
假设我们使用快速排序算法对数组进行排序,对排序算法来说,最简单的数组是什样子的呢?其实间的数组是不需要排序的数组。

所以,基线条件为数组为空或只包含一个元素,这样只需要返回数组即可。
阅读全文…快速排序是一种比选择排序更优秀的排序算法,选择排序运行的时间为:$O(n^2)$,而快速排序法的运行时间为:$O(nlog_2n)$,快速排序使用了D&C的思想(一种分而治之的思想)。下面我们来分析快速排序算法。
假设我们使用快速排序算法对数组进行排序,对排序算法来说,最简单的数组是什样子的呢?其实间的数组是不需要排序的数组。
所以,基线条件为数组为空或只包含一个元素,这样只需要返回数组即可。
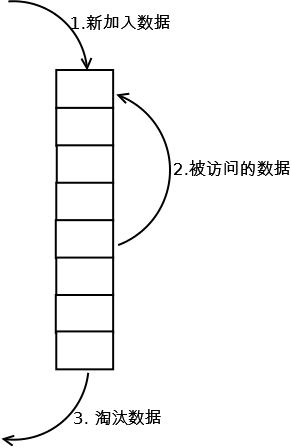
阅读全文…最近在学习memcache缓存时,发现其s数据淘汰策略都是采用LRU算法进行缓存数据的处理。那么什么是LRU算法,这篇深度好文值得一看。
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
本文转载至MySQL 索引设计概要
在关系型数据库中设计索引其实并不是复杂的事情,很多开发者都觉得设计索引能够提升数据库的性能,相关的知识一定非常复杂。

然而这种想法是不正确的,索引其实并不是一个多么高深莫测的东西,只要我们掌握一定的方法,理解索引的实现就能在不需要 DBA 的情况下设计出高效的索引。
本文会介绍 数据库索引设计与优化 中设计索引的一些方法,让各位读者能够快速的在现有的工程中设计出合适的索引。
阅读全文…让我们首先讨论一下为什么想使用 ZooKeeper。ZooKeeper 是一个面向分布式系统的构建块。当设计一个分布式系统时,一般需要设计和开发一些协调服务:
名称服务— 名称服务是将一个名称映射到与该名称有关联的一些信息的服务。电话目录是将人的名字映射到其电话号码的一个名称服务。同样,DNS 服务也是一个名称服务,它将一个域名映射到一个 IP 地址。在分布式系统中,您可能想跟踪哪些服务器或服务在运行,并通过名称查看其状态。ZooKeeper 暴露了一个简单的接口来完成此工作。也可以将名称服务扩展到组成员服务,这样就可以获得与正在查找其名称的实体有关联的组的信息。
锁定— 为了允许在分布式系统中对共享资源进行有序的访问,可能需要实现分布式互斥(distributed mutexes)。ZooKeeper 提供一种简单的方式来实现它们。
同步— 与互斥同时出现的是同步访问共享资源的需求。无论是实现一个生产者-消费者队列,还是实现一个障碍,ZooKeeper 都提供一个简单的接口来实现该操作。您可以在 Apache ZooKeeper 维基上查看示例,了解如何做到这一点(参阅 参考资料)。
配置管理— 您可以使用 ZooKeeper 集中存储和管理分布式系统的配置。这意味着,所有新加入的节点都将在加入系统后就可以立即使用来自 ZooKeeper 的最新集中式配置。这还允许您通过其中一个 ZooKeeper 客户端更改集中式配置,集中地更改分布式系统的状态。
领导者选举— 分布式系统可能必须处理节点停机的问题,您可能想实现一个自动故障转移策略。ZooKeeper 通过领导者选举对此提供现成的支持。
你的J2EE应用是不是运行的很慢?它们能不能承受住不断上升的访问量?本文讲述了开发高性能、高弹性的JSP页面和Servlet的性能优化技术。其意思是建立尽可能快的并能适应数量增长的用户及其请求。在本文中,我将带领你学习已经实践和得到证实的性能调整技术,它将大大地提高你的servlet和jsp页面的性能,进而提升J2EE的性能。这些技术的部分用于开发阶段,例如,设计和编码阶段。另一部分技术则与配置相关。
服务器会在创建servlet实例之后和servlet处理任何请求之前调用servlet的init()方法。该方法在servlet的生命周期中仅调用一次。为了提高性能,在init()中缓存静态数据或完成要在初始化期间完成的代价昂贵的操作。例如,一个最佳实践是使用实现了javax.sql.DataSource接口的JDBC连接池。
DataSource从JNDI树中获得。每调用一次SQL就要使用JNDI查找DataSource是非常昂贵的工作,而且严重影响了应用的性能。Servlet的init()方法可以用于获取DataSource并缓存它以便之后的重用:
Redis是一种key/value型数据库,其中,每个key和value都是使用对象表示的。比如,我们执行以下代码:
|
|
其中的key是message,是一个包含了字符串”message”的对象。而value是一个包含了”hello redis”的对象。
redis共有五种对象的类型,分别是:
| 类型常量 | 对象的名称 |
|---|---|
REDIS_STRING |
字符串对象 |
REDIS_LIST |
列表对象 |
REDIS_HASH |
哈希对象 |
REDIS_SET |
集合对象 |
REDIS_ZSET |
有序集合对象 |
Redis中的一个对象的结构体表示如下:
阅读全文…本文作者: JoonWhee
近期深入学习了ConcurrentHashMap,便整理成一篇博文记录一下,请注意:此博文针对的是JDK1.6,因此如果你看到的源码跟我文中的不同,则可能是由于版本不一样。
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程必须竞争同一把锁。如果容器里有多把锁,每一把锁用于锁容器的其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
我们通过ConcurrentHashMap的类图来分析ConcurrentHashMap的结构。
阅读全文…在多线程情况下,我们可能会使用Hashtable 或者Collections.synchronizedMap(hashMap),这两种方式基本都是对整个 hash 表结构做锁定操作的,这样在锁表的期间,别的线程就需要等待了,无疑性能不高。
那么怎样解决这个问题呢,这样就需要引入ConcurrentHashMap了。
ConcurrentHashMap也是由数组和链表组成,其实在ConcurrentHashMap 的成员变量中,包含了一个 Segment 的数组(final Segment<K,V>[] segments;),而 Segment 是 ConcurrentHashMap 的内部类,然后在 Segment 这个类中,包含了一个 HashEntry 的数组(transient volatile HashEntry<K,V>[] table;)。而 HashEntry 也是 ConcurrentHashMap 的内部类。HashEntry 中,包含了 key 和 value 以及 next 指针(类似于 HashMap 中 Entry),所以 HashEntry 可以构成一个链表。
阅读全文…ConcurrentHashMap 数据结构为一个 Segment 数组,每个Segment 数组存入的是HashEntry 键值对,和链表指针。
面试被问到什么是REST,什么是RESTful风格。一下懵逼,以前只对RESTful稍有了解,对REST没有多大的概念。于是查查有关方面的知识。
REST – REpresentational State Transfer 直接翻译:表现层状态转移(其实就是资源在网络中以某种表现形式进行状态转移)。这个词太术语化。用通俗易懂的话来说,URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作。
REST描述的是在网络中client和server的一种交互形式;REST本身不实用,实用的是如何设计 RESTful API(REST风格的网络接口)。
Server提供的RESTful API中,URL中只使用名词来指定资源,原则上不使用动词。“资源”是REST架构或者说整个网络处理的核心。比如:
lvshen9.github.com/v1/mybook:获取我的book(地址是我瞎写的)
lvshen9.github.com/v1/myfrends:获取我的好友列表
…
阅读全文…